
Fascinating as they may be, Big Data are not without posing problems. Size does not eliminate the problem of quality: because of the very way they are collected, Big Data are unstructured and unsystematized, the sampling criteria are fuzzy, and the classical statistical analyses do not apply very well. The more you zoom in (the more detail you have), the more noise you find, so that you need to aggregate data (that is, to reduce a “big” micro-level dataset to a “smaller” macro one) to detect any meaningful tendency. Analyzing Big Data as they are, without any caution, increases the likelihood of finding spurious correlations – a statistician’s nightmare! In short, processing Big Data is problematic: Although we do have sufficient computational capacity today, we still need to refine appropriate analytical techniques to produce reliable results.
In a sense, the enthusiasm for Big Data is diametrically opposed to another highly fashionable trend in socioeconomic research: that of using randomized controlled trials (RCTs), as in medicine, or at least quasi-experiments (often called “natural experiments”), which enable collecting data under controlled conditions and facilitate detection of causal relationships much more clearly and precisely than in traditional, non-experimental social research. These data have a lot more structure and scientific rigor than old-fashioned surveys – just the opposite of Big Data!
This is just anecdotal evidence, but do a quick Google search for images on RCTs vs. Big Data. Here are the first two examples I came across: on the left are RCTs (from a dentistry course), on the right are Big Data (from a business consultancy website). The former conveys order, structure and control, the latter a sense of being somewhat lost, or of not knowing where all this is heading… Look for other images, I’m sure the great majority won’t be that different from these two.
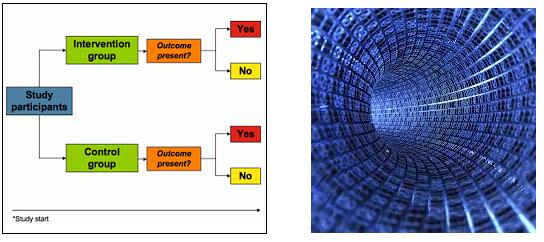
Granted, we also start seeing controlled experiments conducted on a very large scale, usually on the Internet, like this one. They ambition to combine the best of both — size and quality — but I guess what makes their value is the quality more than the size. And after all, there are too few of these scientific endeavors so far to judge.
Unfortunately, most enthusiastic accounts of Big Data, notably in the corporate world, leave aside these issues and simplistically assume that because the sample size is large, and because today’s computers are as powerful as ever before, data analysis will be straightforward. Big Data will certainly add to our society’s capability to retrieve and exploit information, but at the moment, they are not a miraculous solution. More work is needed to deliver what is now only a promise.

1 Comment