I am delighted to be part of a broad reflection, initiated and promoted by Edemilson Paraná, that critically interrogates the convergence of environmental sustainability and digitalization, in a special issue just published in the journal Globalizations. Governments and multi-lateral institutions frame the “twin transition” as a strategy to foster economic growth and durable social prosperity at the same time. However, Paraná argues in his introductory article (co-authored with Rodrigo Santaella-Gonçalves), this agenda is shaped by market logics and geopolitical competition, in ways that ultimately contradict the social and ecological goals it supposedly supports. The special issue has been designed to offer a systemic political-economy perspective on this inconsistency, grounded in critical social sciences and heterodox economics. Overall, it shows how the structural drivers of digitalisation can constrain its green potential and identifies pathways for redirecting the transition towards socially equitable and ecologically sustainable transformations.
Ulysse Gerkens & FARI / “Server Pool” / https://betterimagesofai.org / https://creativecommons.org/licenses/by/4.0/ This image subverts the swimming pool of the Villa Empain, a Brussels contemporary art venue. The pool is drained of its water and filled with computer servers. The image makes visible the massive water consumption required to cool data centers, but also questions the allocation of resources: when enormous budgets shift toward digital infrastructure, what remains for culture?
My own article within this special issue aims to reconcile two separate trends in the study of the impacts of artificial intelligence (AI), one focused on the natural and the other on the social surroundings that supply resources for its production and use. I introduce the concept of the ‘dual footprint’ as a heuristic device to capture the commonalities and interdependencies between them. Originally borrowed from ecology, the concept denotes here the total impacts on the environment and society generated by AI’s production and use. It is an indicator of sustainability insofar as it grasps the degree to which the AI industry is failing to ensure the maintenance of the socio-economic systems and environmental conditions necessary to its production. To develop the concept in this way, it is necessary to (provisionally) renounce some of the accounting flavour of extant footprint measures, allowing for a more descriptive interpretation. In my article, the dual footprint serves as a mapping tool, linking impacts to specific locations and to the people and groups that inhabit them.
I use two in-depth case studies, each illustrating international flows of raw materials (nature) and of labour services (society). Case studies are a preliminary illustration of a broader idea, that will need to be developed further: that the AI industry is a value chain that spans national boundaries and perpetuates inherited global inequalities. Specifically, I use the case of Argentina as a provider to the United States and Madagascar as a provider to France, Japan and South Korea. It appears that the countries that drive AI development (here, the United States, France, Japan and South Korea) generate a massive demand for inputs and trigger social costs that, through the value chain, largely fall on more peripheral actors (here, Argentina and Madagascar). While Argentina and Madagascar differ under many respects, in both cases initial hopes of jobs and prosperity have failed to materialise as predominant outsourcing arrangements reinforce informality and precariousness without preventing environmental damage. Put differently, the arrangements in place distribute the costs and benefits of AI unequally, resulting in unsustainable practices and preventing the upward mobility of relatively more disadvantaged countries. The concept of the dual footprint is useful because it grasps how the environmental and social dimensions of the dual footprint emanate from similar underlying socio-economic processes and geographical trajectories.
A prior presentation of this idea can be found here.
A pre-print version of the article (green open access) can be found here.
There are two main ways in which a discipline like sociology engages with artificial intelligence (AI) and is affected by it. In a previous post, I discussed how the sociology of AI understands technology as embedded in socio-economic systems and takes it as an object for research. Here, focus is on sociology with AI, indicating that the discipline is integrating AI into its methodological toolbox.
AI technologies were designed for other-than-research purposes, but they may be repurposed. The editors of a special issue of Sociologica last year stress that, ten years ago, digital methods presented similar challenges: for example, using tweets to make claims about the social world required us to understand how people used Twitter in the first place. We also needed to understand which people used Twitter at all, and what spaces of action the architecture and Terms of Use of this platform allowed. Likewise, using AI technologies can serve sociologists insofar as efforts are made to understand the technological (and socio-economic) conditions that produced them. Because AI systems are typically blackboxed, this requires, to begin with, developing exploration techniques to navigate them. For example, the plot below is from a recent paper that asked five different LLMs to generate religious sermons and compared the results (readability scores) by religious traditions and race. It finds that Jewish and Muslim synthetic sermons were constructed with significantly more difficult reading levels than were those for evangelical Protestants, and that Asian religious leaders were assigned more difficult texts than other groups. It is a way to uncover how models treat religious and racial groups differently, although it remains difficult to detect precisely which factors affect this result.
Robust regression coefficients predicting readability scores by religion, race, and model. Source: Tom J.C., Ferguson T.W. & Martinez B.C. 2025. Religion and racial bias in Artificial Intelligence Large Language Models. Socius: Sociological Research for a Dynamic World, 11. https://doi.org/10.1177/23780231251377210
That said, how can AI help us methodologically? To answer this question, it is useful to look at qualitative and quantitative approaches separately. Qualitative research, traditionally viewed and practiced as an intensely human-centred method, may seem at first sight incompatible with it. However, use of computer-assisted qualitative data analysis (with tools such as Nvivo) is now common among qualitative researchers, though it faced some degree of scepticism at the beginning. Attempts to leverage AI move forward this agenda, and the most common application so far is automated transcription of interviews through speech recognition technologies. AI-powered tools make this otherwise tedious task more efficient and scalable. A recent special issue of the International Journal of Qualitative Methods maps a variety of other usages, less common and more experimental: for example, considering that even the best models for audio transcription are not as accurate as humans, LLMs appear as tools to facilitate and speed up transcription cleaning. There are also some attempts at using LLMs as instruments for coding and thematic analysis: for example, some authors have examined inter-coder reliability between ‘human only’ and ‘human-AI’ approaches. Others have used AI image generation like vignettes – as a tool for supporting interview participants in articulating their experiences. Overall, the use of AI remains experimental and marginal in the qualitative research community. Those who have undertaken these experiments find the results encouraging, but not perfect.
In quantitative research, some AI tools are already (relatively) widely used: in particular, natural language processing (NLP) to process textual data like corpora from the press or media. More recent applications leverage generative AI, especially large language models (LLM). Outside practices like literature review and code generation/debugging, which are common to multiple disciplines, three applications are specifically sociological and worth mentioning. First, in experimental research, there are some attempts to examine how the introduction of AI agents in interaction games shapes the behaviour of the humans they play with. As discussed by C. Bail in an insightful PNAS article, the extent to which generative AI is capable of impersonating humans is nevertheless subject to debate, and it will probably evolve over time. Second, L. Rossi and co-authors outline that in agent-based models (ABM), an idea is to use LLMs to create agents that are more capable of capturing a larger spectrum of human behaviours. While this approach may provide more realistic descriptions of agents, it re-ignites a long-standing debate in the field: indeed, many believe that increasing the complexity of agents is undesirable when emergent collective dynamics can emerge from more parsimonious models. It is also unclear how the performance of LLMs within ABMs should be evaluated. Shall we say that they are good if they reproduce known collective dynamics within ABMS? Or, should they be assessed based upon their capacity to predict real-world outcomes? Third, in survey research, the question has arisen whether LLMs can simulate human populations for opinion research. Some studies have tested this possibility, with mixed results. The most recent available evidence, in an article by J. Boelaert and co-authors, is that: 1) current LLMs fail to accurately predict human responses, 2) they do so in ways that are unpredictable, as they do not systematically favor specific social groups, and 3) their answers exhibit a substantially lower variance between subpopulations than what is found in real-world human data. In passing, this is evidence that so-called ‘bias’ does not necessarily operate as expected – LLM errors do not stem primarily from unbalanced training data.
These applications face specific ethical challenges. First, studies that require humans to interact with AI may expose them to offensive or inaccurate information, the so-called ‘AI hallucinations’. Second, there are new concerns about privacy and confidentiality. Most GenAI models are the private property of companies: if we use them to code in-depth interviews about a sensitive topic, the full content of these interviews may be shared with these companies, often not bound by the same standards and regulations in terms of personal data protection. Third, the environmental impact of these models is high, in terms of energy to run the system, water to cool servers in data centres, metal extraction to build devices, and production of e-waste. The literature on AI-as-object also warns that there is a cost in terms of the unprotected human work of annotators.
Another limitation is that is that research with Generative AI is difficult to replicate. These models are probabilistic in nature: even identical prompts may produce different outputs, in ways that are not well understood as of today. Also, models are constantly being fine-tuned by their producers in ways that we as users do not control. Finally, different LLMs have been found to produce substantially different results in some cases. Many of these issues are due to the proprietary nature of most models – so much so that some authors like C. Bail believe that open-source models devoted to, and controlled by, researchers can help address some of these challenges.
Overall, AI has slowly entered the toolbox of the sociologist, and except for some applications that are now commonplace (from automated transcriptions to NLP), its use has not completely revolutionised practices. This pattern is not exclusive to sociology. My own study of the diffusion of AI in science until 2021, as part of the ScientIA project led by F. Gargiulo, showed limited penetration in almost all disciplines, although the last two years have seen a major acceleration. The opportunities that AI offers are promising, although a lot are more hypothetical than real at the moment. We still see calls that invite sociologists and social scientists to embrace AI, but the number of realizations is still small. Almost all applications devote time to consider the epistemological, methodological, and substantive implications. A question that often emerges concerns the nature of bias. The AI-as-object perspective challenges the language of bias, and we see the same here, though from a different perspective. There’s still no shared definition of bias (or any substitute for this term). More generally, patterns are similar in qualitative and quantitative studies. The guest-editors of last year’s special issue of Sociologicasuggest that, like digital methods 10-15 years ago, generative AI is supporting a move beyond the traditional qualitative/quantitative divide.
Concluding, both Sociology-of-AI and Sociology-with-AI exist and are important, but they are not well integrated. This is one of the bottlenecks for the development of the methodological toolbox of sociology, but also for the development of an AI that is useful and positive for people and societies. In part, this may be due to lack of adequate (technical) training for part of the profession, or to the absence of guidelines (for ethics and/or scientific integrity). But perhaps, the real obstacles are less immediately visible. One of them is the difficulty to judge the uptake of AI in our discipline: are we just feeding the hype if we use it? Or are we missing a major opportunity to make sociology more relevant/stronger if we don’t? The other concerns the questions and issues that go beyond the specificities of sociology. How to continue interacting with other disciplines, while upholding the distinctive contribution of sociology?
A few years ago, when hopes to leverage technology to build a more humane “sharing” economy had not yet completely vanished, it was often believed that the most interesting policy experiments were to be found at the local level of cities, not states. One of those was the urban-planning concept of a 15-minute city, aiming to make any essential amenities such as schools and shops accessible within a 15-min walk or bike ride. Launched in Paris before receiving enthusiastic support worldwide, it was part of the current mayor’s latest re-election campaign.
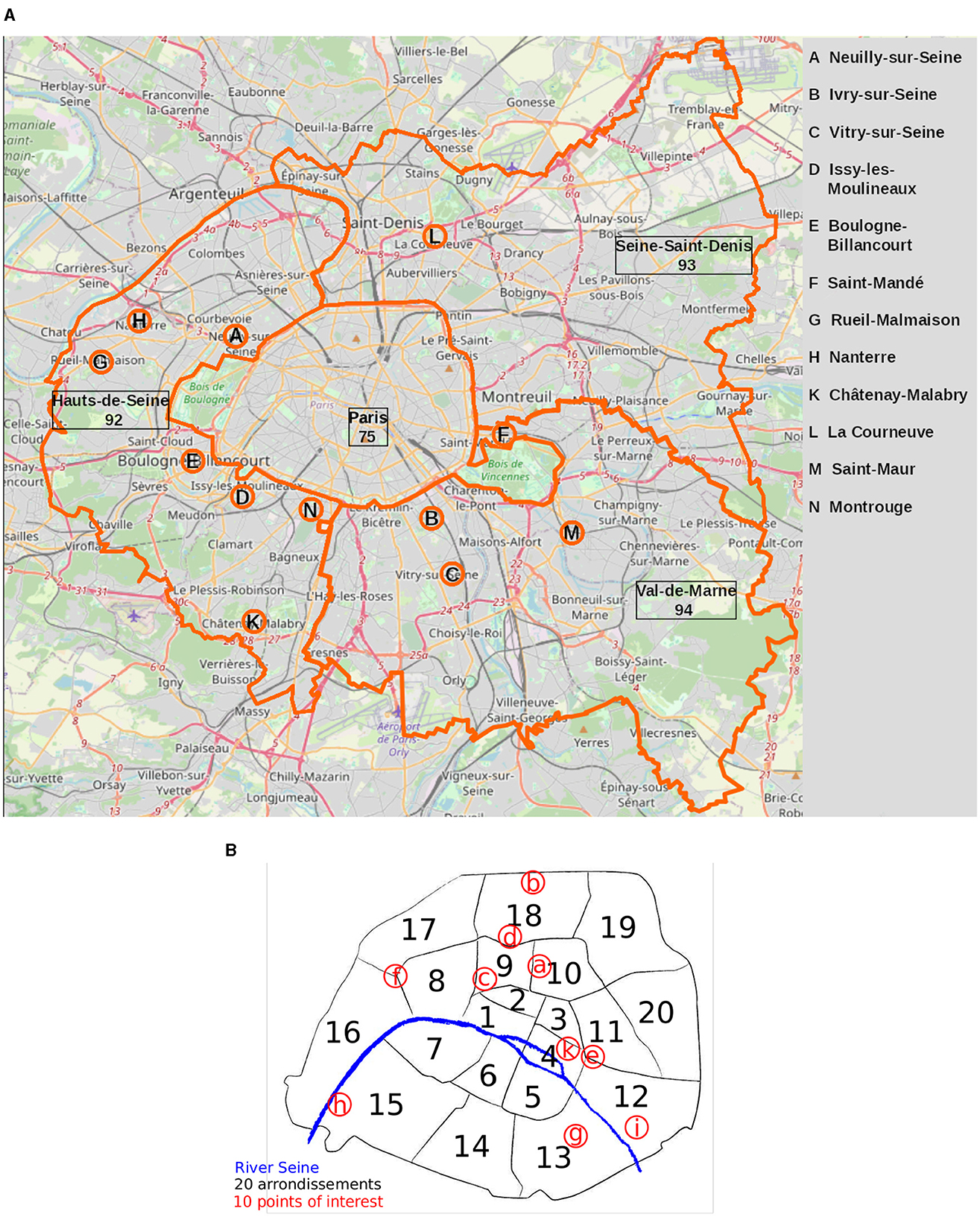
Fast forward to today, and how actually far is Paris from the 15-min goal? Sarah J. Berkemer and I have endeavoured to answer this question in a just-published article (available in open access!) with three brilliant ENSAE students (Marie-Olive Thaury, Simon Genet and Léopold Maurice). We harness open map data from the large participatory project Open Street Map and geo-localized socio-economic data from official statistics (Insee) to fill this gap.
While the city of Paris is rather homogeneous, we show that it is nonetheless characterized by remarkable inequalities between a highly accessible city centre (though with some internal differences in terms of types of amenities) and a less equipped periphery, where lower-income neighborhoods are more often found. Heterogeneity increases if we consider Paris together with its immediate surroundings, the “Petite Couronne,” where large numbers of daily commuters and other users of city facilities live.
We find that this ambitious urban planning objective cannot be achieved without addressing existing socio-economic inequalities, and that especially in a big city like Paris, it cannot be confined within the narrow boundaries of the municipality itself, without also including the city’s immediate surroundings.
One reason why I am particularly proud of this work is that it demonstrates how far research-informed teaching can go. Most higher education is about familiarizing students with generally accepted and confirmed knowledge, without going beyond the state of the art. This is certainly important and in all cases a “safe” bet, but does not give students a sense of what it means to push the boundaries further. This project was an opportunity to do so. It gave students the role of researchers – our peers – letting them play the role in full and showing them all the back-office work that lies behind publications (from drafting to responding to reviews and copy-editing), and that is (too) often occluded from students’ view. There’s probably more to experiment around this model.
We are excited to announce the 6th Conference of the International Network on Digital Labor (INDL-6), scheduled to take place 9-11 October, 2023. The conference aims to bring together experts from various fields to discuss the latest research findings and share ideas on the topic of Digital Labor in the Wake of Pandemic Times. Following long-term technological trends as well as exogenous shocks, the field of digital labor is constantly expanding. This year’s INDL conference will be an excellent opportunity to exchange insights and perspectives, as well as a great way to make new friends among researchers, workers, policymakers, and practitioners who study the future of work, social justice, platforms, and artificial intelligence (AI).
The INDL-6 conference will be held in-person at the Weizenbaum Institute for the Networked Society in Berlin, Germany. It is co-organized by the International Labor Organization (ILO), the Digital Platform Labor (DiPLab) group, and Wissenschaftszentrum Berlin für Sozialforschung (WZB).
We encourage all interested researchers, post-graduate students, and practitioners to submit proposals that address aspects of digital labor, including but not limited to: gig economy, online labor, workplace surveillance, algorithmic management, AI-assisted recruiting, remote work, employee well-being, inequality, policy responses to Covid-19 crisis, regulation, organizing digital workers, gender and work, LGBTQ+ workers, intersectionality, disability, inclusion, AI, decolonial lens, informal labor markets, generative AI and work.
We welcome submissions that are interdisciplinary in nature and strongly encourage proposals by researchers and practitioners from the Global South across all topics.
The Call for Papers is available here and the deadline is 12 April.
We organized the one-day conference AIGLe on 27 October 2022 to present the outcomes of interdisciplinary research conducted by our DiPLab teams in French-speaking African countries (ANR HuSh Project) and Spanish-speaking countries in Latin America (CNRS-MSH TrIA Project). Both initiatives study the human labor necessary to generate and annotate the data needed to produce artificial intelligence, to check outputs, and to intervene in real time when algorithms fail. Researchers from economics, sociology, computer science, and linguistics shared exciting new results and discussed them with the audience.
AIGLe is part of the project HUSh (The HUman Supply cHain behind smart technologies, 2020-2024), funded by ANR, and the research project TRIA (The Work of Artificial Intelligence, 2020-2022), co-financed by the CNRS and the MSH Paris Saclay. This event, under the aegis of the Institut Mines-Télécom, was organized by the DiPLab team with support of ANR, MSH Paris-Saclay and the Ministry of Economy and Finance.
PROGRAM 9:00 – 9:15 Welcome session
9:15 – 10:40 – Session 1 – Maxime Cornet & Clément Le Ludec (IP Paris, ANR HUSH Project): Unraveling the AI Production Process: How French Startups Externalise Data Work to Madagascar. Discussant: Mohammad Amir Anwar (U. of Edinburgh)
10:45 – 11:00 Coffee Break
11:00 – 12:30 – Session 2 – Chiara Belletti and Ulrich Laitenberger (IP Paris, ANR HUSH Project): Worker Engagement and AI Work on Online Labor Markets. Discussant: Simone Vannuccini (U. of Sussex)
12:30 – 13:30 Lunch Break
13:30 – 15:00 Session 3 – Juana-Luisa Torre-Cierpe (IP Paris, TRIA Project) & Paola Tubaro (CNRS, TRIA Project): Uninvited Protagonists: Venezuelan Platform Workers in the Global Digital Economy. Discussant: Maria de los Milagros Miceli (Weizenbaum Institut)
15:15 – 15:30 Coffee Break
15:30 – 17:00 Session 4 – Ioana Vasilescu (CNRS, LISN, TRIA Project), Yaru Wu (U. of Caen, TRIA Project) & Lori Lamel (LISN CNRS): Socioeconomic profiles embedded in speech : modeling linguistic variation in micro-workers interviews. Discussant: Chloé Clavel (Télécom Paris, IP Paris)
Today’s artificial intelligence, largely based on data-intensive machine learning algorithms, relies heavily on the digital labour of invisibilized and precarized humans-in-the-loop who perform multiple functions of data preparation, verification of results, and even impersonation when algorithms fail. This form of work contributes to the erosion of the salary institution in multiple ways. One is commodification of labour, with very little shielding from market fluctuations via regulative institutions, exclusion from organizational resources through outsourcing, and transfer of social reproduction costs to local communities to reduce work-related risks. Another is heteromation, the extraction of economic value from low-cost labour in computer-mediated networks, as a new logic of capital accumulation. Heteromation occurs as platforms’ technical infrastructures handle worker management problems as if they were computational problems, thereby concealing the employment nature of the relationship, and ultimately disguising human presence. My just-published paper highlights a third channel through which the salary institution is threatened, namely misrecognition of micro-workers’ skills, competencies and learning. Broadly speaking, salary can be seen as the framework within which the employment relationship is negotiated and resources are allocated, balancing the claims of workers and employers. In general, the most basic claims revolve around skill, and in today’s ‘society of performance’ where value is increasingly extracted from intangible resources and competencies, unskilled workers are substitutable and therefore highly vulnerable. In human-in-the-loop data annotation, tight breakdown of tasks, algorithmic control, and arm’s-length transactions obfuscate the competence of workers and discursively undermine their deservingness, shifting power away from them and voiding the equilibrating role of the salary institution.
Following Honneth, I define misrecognition as the attitudes and practices that result in people not receiving due acknowledgement for their value and contribution to society, in this case in terms of their education, skills, and skill development. Platform organization construes work as having little value, and creates disincentives for micro-workers to engage in more complex tasks, weakening their status and their capacity to be perceived as competent. Misrecognition is endemic in these settings and undermines workers’ potential for self-realization, negotiation and professional development.
My argument is based on original empirical data from a mixed-method survey of human-in-the-loop workers in two previously under-researched settings, namely Spain and Spanish-speaking Latin America.
In the late 2000s, voices suggesting that our societies might be nearing the ‘end of privacy’ became increasingly deafening. Our cultural, political and regulatory environment was on the verge of major transformation – so went the narrative. Businesses rejoiced as notoriously, less privacy and more information oils the economy.
In a video interview with Italian media Idee Sottosopra, I review the courses of action taken by various stakeholders, in particular Internet companies, and examine their conflicts and controversies. I show how the very concept of privacy, inherited from a long legal and judicial tradition, should be revised and redefined to appropriately describe today’s online interactions.
Overall, there is no deterministic and inevitable tendency to exclude privacy from our societies, but rather a tension between social forces for and against privacy, which has accompanied the advent of the digital economy and especially social media. The positions of stakeholders, especially users, are often ambiguous, and social media companies attempted to leverage this ambiguity to their own advantage.
Yet civil society reactions have been stronger and stronger, and after initial David-vs-Goliath attempts of individuals and small associations, more and more authoritative institutions have taken seriously the defence of privacy. We are no longer left to costly and little-visible individual choices, and especially after entry into force of GDPR in Europe, we have now an unprecedented opportunity to act at a more systemic level.
Big Data. L’ipotesi della fine della della Privacy | Società Digitale | Idee Sottosopra
Together with sociologist Antonio A. Casilli and economist Ulrich Laitenberger, I have recently received ANR (French National Research Agency) funding for a new study of human inputs – mostly platform-mediated work in the production of artificial intelligence solutions. In our project called HUSH (Human supply chain behind smart technologies) we aim to shed light on the whole ecosystem linking platforms, workers and their clients demanding data-related and algorithmic services.
For this project, we are now looking for a
PhD researcher in digital economics
The position provides the opportunity to focus strongly on research, in a very active environment. The team has collaborations with different online platforms and has collected data sets from the web, which can be used by the applicant for their thesis. The focus of the current position is to work on the economic aspects of platform-mediated work, using quantitative analyses. Two other PhD students (in sociology) have already been recruited for this project and work on related topics.
The starting date is January 2020 (a later starting date is also possible). As per national regulations, the annual stipend will be about 1,600 euros per month, with possibility to obtain a complement for extra activities such as teaching. Social security and professional training are provided. Additional funding is available to present your research at international conferences and workshops. The position will be based at the new campus of Telecom Paris in Palaiseau, in the direct neighborhood of École Polytechnique and ENSAE.
Your profile
Applicants should have successfully completed a Master’s degree in economics, socio/economic data science or related disciplines, or expect completion at the beginning of the year 2020. They should have a strong interest in digital platforms, from the perspective of industrial organization or labor economics, and have an empirical focus (econometrics, data science). They should aim at developing programming skills and have an interest in the evaluation of internet data. Fluency in English is required; knowledge of French is advantageous, but not essential.
Please submit a cover letter, a curriculum vitae, a transcript of records (listing all subjects taken and their grades), and contact details of one to two referees by November 15, 2019 to Ulrich Laitenberger ( laitenberger@enst.fr ).
Update: applications open until December 15, 2019.
Table ronde, Sciences Po Paris, 6 décembre 2018, 18h00
Pour que la recherche en sciences sociales puisse pleinement tirer profit des grandes bases de données numériques, un verrou reste à lever : l’accès à ces données est limité, inégalement distribué, et entouré d’un flou juridique et déontologique. Nous proposons d’en discuter à l’occasion de la parution du numéro spécial de la Revue Française de Sociologie sur “Big data, sociétés et sciences sociales” (n. 59/3). Cette table ronde réunit les chercheur.e.s avec d’autres parties prenantes publiques et
privées.
Avec :
Garance Lefèvre, Policy senior associate, Uber
Roxane Silberman, Conseillère scientifique, Centre d’Accès Sécurisé aux Données (CASD)
Sophie Vulliet-Tavernier, Directrice des relations avec les publics et la recherche, Commission Nationale de l’Informatique et des Libertés (CNIL)
Les auteurs du numéro spécial.
Modérateurs : Gilles Bastin (Univ. Grenoble Alpes) et Paola Tubaro (CNRS), coordinateurs du numéro spécial.
Entrée libre et gratuite, dans la limite des places disponibles: pour s’inscrire, cliquez ici.
Accès : Sciences Po, salle Goguel. Entrée par le 27 rue Saint-Guillaume, 75007 Paris (traverser le jardin et prendre l’ascenseur jusqu’au dernier étage). La table ronde est organisée par la Revue Française de Sociologie en collaboration avec les Presses de Sciences Po. Elle sera suivie d’un pot.