(English version below)
J’ai le plaisir d’annoncer la soutenance de mon habilitation à diriger des recherches en sociologie intitulée :
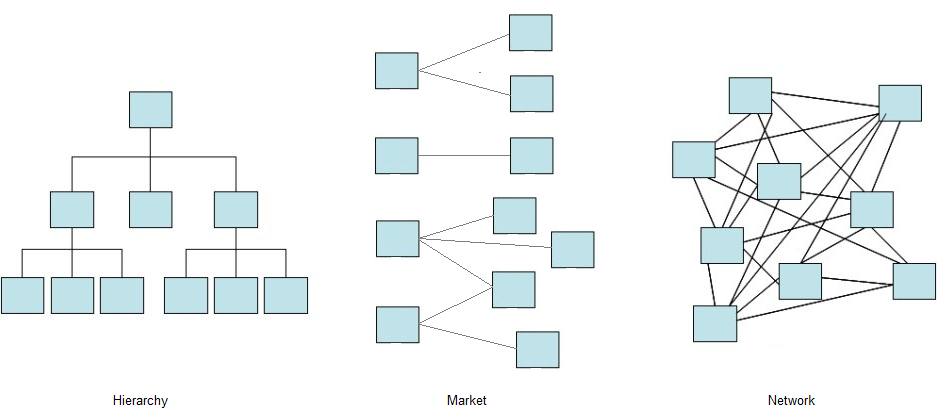
Décrypter la société des plateformes: Organisations, marchés et réseaux dans l’économie numérique.
Cette soutenance aura lieu le mercredi 11 décembre 2019 à Sciences Po Paris, 9 rue de la chaise, salle 931, à 10h00.
Si vous souhaitez venir, merci de confirmer votre présence grâce à ce lien car les personnes externes à Sciences Po ne pourront pas accéder à la salle si elles ne sont pas annoncées.
Le jury sera composé de :
- M. Gilles Bastin, Professeur des universités, IEP de Grenoble (rapporteur)
- M. Rodolphe Durand, Professeur, HEC Paris
- M. Emmanuel Lazega, Professeur des universités, IEP de Paris (garant et rapporteur)
- Mme Béatrice Milard, Professeure des universités, Université de Toulouse Jean Jaurès (rapporteure)
- M. José Luís Molina González, Professeur, Universitat Autònoma de Barcelona
- M. Tom A.B. Snijders, Professeur, Rijksuniversiteit Groningen
La soutenance sera suivie d’un pot.
Résumé
Le manuscrit original conceptualise la récente montée en puissance des platesformes numériques selon trois dimensions principales : leur nature de dispositifs de coordination alimentés par les données, les transformations du travail qui en découlent, et les promesses d’innovation sociétale qui les accompagnent. L’ambition globale est de décortiquer le rôle de coordination de la plateforme et sa position à l’horizon de la dualité classique entreprise – marché. Il s’agit aussi de comprendre précisément comment elle utilise les données pour ce faire, où elle amène le travail, et comment elle gère des projets d’innovation sociale. Je prolonge cette analyse pour faire apparaître la continuité entre la société actuelle dominée par les plateformes et la « société organisationnelle », montrant que les plateformes sont des structures organisées qui distribuent les ressources, produisent des asymétries de richesse et de pouvoir, et repoussent l’innovation sociale vers la périphérie du système. Je discute des implications de ces tendances pour les politiques publiques, et propose des pistes pour la recherche future.
I am pleased to announce the defense of my habilitation to direct research in sociology entitled:
Decoding the platform society: Organizations, markets and networks in the digital economy
This defense will take place on Wednesday, 11 December 2019 at Sciences Po Paris, 9 rue de la chaise, room 931, at 10am.
If you wish to attend, please confirm your presence through this link because people who are external to Sciences Po will be denied access to the room if they are not announced.
Members of the jury are:
- Prof. Gilles Bastin, IEP de Grenoble (referee)
- Prof. Rodolphe Durand, HEC Paris
- Prof. Emmanuel Lazega, IEP de Paris (advisor and referee)
- Prof. Béatrice Milard, Université de Toulouse Jean Jaurès (referee)
- Prof. José Luís Molina González, Universitat Autònoma de Barcelona
- Prof. Tom A.B. Snijders, Rijksuniversiteit Groningen
There will be drinks after the defense.
Abstract
The original manuscript conceptualizes the recent rise of digital platforms along three main dimensions: their nature of coordination devices fueled by data, the ensuing transformations of labor, and the accompanying promises of societal innovation. The overall ambition is to unpack the coordination role of the platform and where it stands in the horizon of the classical firm – market duality. It is also to precisely understand how it uses data to do so, where it drives labor, and how it accommodates socially innovative projects. I extend this analysis to show continuity between today’s society dominated by platforms and the “organizational society”, claiming that platforms are organized structures that distribute resources, produce asymmetries of wealth and power, and push social innovation to the periphery of the system. I discuss the policy implications of these tendencies and propose avenues for follow-up research.