After having studied the impacts of AI on labour and society for years, I am now joining forces with colleagues interested in the materiality of AI and its appetite for natural resources – energy, water, and land. As part of the collaborative project SEED, with the DiPLab and FAIR teams, I spent almost a month doing fieldwork in Chile to dig deeper into the matter.
Google’s data center in Quilicura, Chile.
Chile is an especially interesting case study. In the global industry of AI, it is a peripherical country; but it is a rich country, highly digitized and with the best connectivity in the world, where use of AI tools is already widespread. It is not a leader, but it is a hub that provides resources. In Chile, all the phases of the supply chain of AI can be observed, starting from the mines of rare earths in Penco, and of copper and lithium in the Atacama Desert, to the data centers that populate (especially, though not only) the Quilicura area, the submarine cables that connect Valparaiso to the world through the Pacific, and the research labs in Santiago. Chile is also emblematic of the frictions that may arise as a result, and of the potential societal reactions – the most telling example being the quili.ai initiative to raise worldwide awareness about the consumption of water by data centers and the ensuing risks for the population. Yet, not all the potentially concerned actors have sufficient capacity to anticipate these impacts, especially outside the capital.
After an interdisciplinary panel at the intersection of AI, mineral extraction, ecology, and planetary habitability at Museo Chileno de Arte Precolombino, Santiago, 2 July 2026.
During almost a month, I could address these issues very productively with fellow researchers, policymakers, environmental judges, activists, and artists. The result is a rich baggage of information, and an extremely helpful basis for further research and action.
Contemporary debates on AI and labour often focus on quantitative impacts, such as potential job losses. Yet, the qualitative question of how AI reshapes the experience of work is equally critical. A recent open-access book chapter that I co-authored with Antonio A. Casilli examines these transformations, highlighting their already tangible, if not yet final, effects on job quality.
The analysis starts with AI deployment, that is, the introduction of AI solutions into the workplace – for example, use of automated transcription tools. It is typically framed as a productivity enhancer that can improve job quality by making work more engaging – and in some cases, even safer. However, critics argue that firms often use AI to intensify labour through tighter managerial control and surveillance. In this scenario, AI may degrade job quality by restricting autonomy, reinforcing algorithmic management, and limiting workers’ ability to negotiate their roles or pace.
But before AI tools reach the workplace, they must be designed, built, and marketed. Today’s AI production relies heavily on machine learning, which requires vast datasets. This process involves extensive “data work,” performed by myriad lower-level workers in three key functions: preparation (data generation and annotation), verification (quality control of AI outputs), and impersonation (manually performing tasks meant to be automated). While this process increases labour demand the quality of data work is often poor, with low wages, job insecurity, and misrecognition of skills. The root of these issues lies in labour platformization.
The Preparation – Verification – Impersonation functions of data work in AI production. Source: Tubaro et al. 2020.
To see this, let’s first take a step back and consider that most data work is procured through outsourcing (shifting lower-value functions outside the firm) and offshoring (relocating work to lower-wage countries). These practices exclude externalised workers from the resources of lead firms, creating a “planetary market” where AI companies in the US and Europe source labour from countries like Venezuela or Madagascar. Digital platforms amplify these trends, enabling on-demand outsourcing to precarious micro-providers globally. Platformization thus exacerbates the negative effects of outsourcing and offshoring, degrading job quality.
Platformisation is best understood at the crossroads of two broader socioeconomic tendencies. First, the “fissured workplace“, where companies market goods or services without employing all those who contribute to their design, assembling or delivery. This model heightens insecurity, as metrics and surveillance systems erode autonomy and increase stress. Offshore platform workers, in particular, face isolation, losing traditional workplace camaraderie and support. Second, “dispersion“, the constant need to manage interruptions, multitask, and prioritise competing demands. AI-driven tools, such as real-time scheduling algorithms and productivity trackers, intensify dispersion, blurring boundaries between professional and personal life and increasing mental strain.
Overall, then, the effects of AI on job quality are mixed. While AI deployment can enhance productivity and safety, it often intensifies labour and undermines autonomy. Meanwhile, AI production creates jobs, but these are frequently precarious and low-quality. Understanding these dynamics is essential for shaping equitable futures that leverage the potential of contemporary technologies while safeguarding labour rights and well-being.
This is not a story of technological determinism. AI alone does not destroy jobs or degrade their quality; rather, its impacts stem from the broader economic forces that shape its presence and role in today’s economies. The above artwork captures this idea by foregrounding humanity’s collective endeavour in building artificial intelligence, drawing inspiration from Persian miniature painting. In sum, the future of work in the age of AI will hinge on political choices about production organisation and the distribution of its benefits and costs.
The book chapter can be found as: Casilli, A.A. & Tubaro, P. 2026. “What is AI Doing to Job Quality? Platformization, Fissured Workplaces and Dispersion”. Chapter 3 in A. Piasna & J. Leschke (eds.) Job Quality in a Turbulent Era. Cheltenham, UK: Edward Elgar Publishing, pp. 45-60, https://doi.org/10.4337/9781035343485.00009
A video of the launching event of the book – including my presentation of the chapter – is available here.
The impacts of artificial intelligence (AI) on the natural and social surroundings that supply resources for its production and use have been studied separately so far. In a new article, part of a forthcoming special issue of the journal Globalizations, I introduce the concept of the ‘dual footprint’ as a heuristic device to capture the commonalities and interdependencies between them. Originally borrowed from ecology, the concept denotes in my analysis the total impacts on the natural and social surroundings that supply the resources necessary for AI’s production and use. It is an indicator of sustainability insofar as it grasps the degree to which the AI industry is failing to ensure the maintenance of the social systems, economic structures, and environmental conditions necessary to its production. To develop the concept in this way, it is necessary to (provisionally) renounce some of the accounting flavour of extant footprint measures, allowing for a more descriptive interpretation. In my article, the dual footprint primarily serves as a mapping tool, linking impacts to specific locations and to the people and groups that inhabit them.
My analysis draws on recent research that challenges idealized narratives of AI as the sole result of mathematics and code, or as the fancied machinic replacement of human brains. The production of AI relies on global value chains which, like those of textiles and electronics, take shape within the broader context of globalization, its long-standing trends of outsourcing and offshoring, and the cross-country disparities on which it thrives.
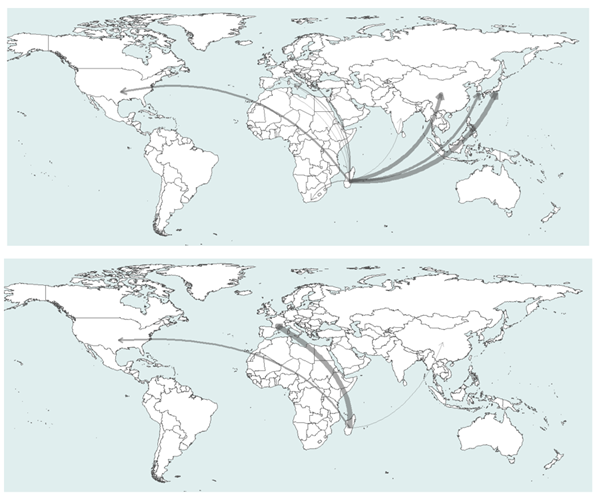
The argument is based on two case studies, each illustrating AI-induced cross-country flows of natural resources and data labour. The first involves Argentina as a supplier to the United States, while the second includes Madagascar and its primary export destinations: Japan and South Korea for raw materials, France for data work. These two cases portray the AI landscape as an asymmetric structure, where the countries that lead the tech race generate a massive demand for imports of raw materials, components, and intermediate goods and services. Core AI producers trigger the footprint and therefore should bear responsibility for it, but the pressure on (natural and social) resources and the ensuing impacts occur predominantly elsewhere. Cross-country value chains shift the burden toward more peripheral players, obscuring the extent to which AI is material- and labour-intensive.
Flows of raw materials (mainly nickel and cobalt from the Ambatovy mining project) from Madagascar to East Asia and, to a lesser extent, Europe and North America (top); flows of data work services from Madagascar to France, followed by North America and to a lesser extent, East Easia (bottom). Madagascar, one of the poorest countries in the world, contributes to state-of-the-art AI production without managing to move up the value chain.
This drain of resources toward AI engenders adverse effects in peripheral countries. Mining notoriously generates conflicts, and data work conditions are so poor that other segments of society – from local employers to workers’ families and even informal-economy actors – must step in to cover part of the costs. The current arrangements thus fail to ensure their own sustainability over time. Additionally, the aspirations of these countries to leverage their participation to the AI value chain as a development opportunity, and to transition toward leading positions, remain unfulfilled.
The dual footprint can fruitfully dialogue with the critical literature that leverages the concepts of extractivism (for example, Cecilia Rikap‘s concept of “twin” extractivism) and dependency (as theorised for example by Jonas Valente and Rafael Grohmann). Its contribution lies mainly in the effort to operationalise the ideas of more abstract social theories, while also facilitating mutual enrichment between different literatures.
The paper was developed as part of an initiative on ‘The Political Economy of Green-Digital Transition‘, organised by Edemilson Paraná in 2024 at LUT University in Finland. Further, the idea that the environmental and social dimensions of AI production emanate from similar underlying socio-economic processes and geographical trajectories constitutes the foundation of SEED – Social and Environmental Effects of Data Connectivity, a new DiPLab project that investigates how data extraction and material extraction are deeply interconnected. It stems from a collaboration with Núcleo Milenio FAIR at the Pontificia Universidad Católica de Chile and compares data and material infrastructures in Europe and South America.
Following the success of the inaugural INDL-MEA Conference in 2024, the second event of the Middle East and Africa chapter of the International Network on Digital Labor (INDL-MEA-2) will take place exclusively online on 25-26 November 2025. The conference will serve as a key regional forum for researchers, policymakers, and practitioners engaged in studying and shaping the future of digital labor, gig work, data work, content moderation, and technology-related jobs in the Middle East and Africa.
Digital labor continues to evolve as a defining feature of global and regional economies, shaping employment opportunities, economic structures, and policy debates. The Middle East and Africa present unique dynamics in digital labor, characterized by platformization, algorithmic management, labor informality, and digital entrepreneurship, alongside issues of regulation, fair work practices, and digital workers’ agency.
With INDL-MEA’s second edition, we aim to enhance interdisciplinary and policy-relevant insights into platform work, automation, labor protections, and digital rights in the region. The programme is available here, and it is still possible to register here.
There are two main ways in which a discipline like sociology engages with artificial intelligence (AI) and is affected by it. The sociology of AI understands technology as embedded in socio-economic systems and takes it as an object for research. Sociology with AI indicates that the discipline is also integrating AI into its methodological toolbox. Based on a talk that I gave at this year’s annual meeting of the European Academy of Sociology, I’ll give in what follows a brief overview of both. As a disclaimer, I have no pretention to be exhaustive. To narrow down the topic, I have chosen to focus on sociology specifically (rather than neighboring fields), and to rely only on already published, peer-reviewed research.
Let’s start with the sociology of AI, which I’ll illustrate with the help of the above artwork. Its aim is to demonstrate that even if there is a sense of magic in looking at the outputs of an AI system, the data on which it is based has a human origin. This work explores this idea through the symbolism of the mirror and reflection: beyond the magic, these outputs are a reflection of society. Sociological perspectives matter because they can help bring these social and human origins to the fore. In 2021, Kelly Joyce and her coauthors called for more engagement of sociologists in outlining a research agenda around these topics. Compared to other disciplines, we have a thicker understanding of the intersectional inequalities and social structures that interact with AI.
Why does the quasi-absence of sociology matter? I’ll answer this question through a 2022 paper, written by two sociologists but published in a computer science conference. The starting point is that early studies framed AI-related societal problems in terms of bias. For example, the above-mentioned report on predictive policing was entitled “machine bias”. This language points to technical corrections as remedy, but it cannot account for the social processes underway that comprise, among other things, increasing surveillance and privacy intrusion to collect more and more data (see image below). De-biasing may thus be insufficient to prevent injustice or inequality. A sociologically informed approach reveals that key questions are about power: who owns data and systems, whose worldviews are being imposed, whose biases we are trying to mitigate.
In recent years, more substantial contributions have been made within sociology. For example, there was a special issue of Socius last year on “Sociology of Artificial Intelligence”, and another one is forthcoming in Social Science Computer Review, entitled “What is Sociological About AI?”. I’ll mention a non-exhaustive selection of topics and findings. First, sociologists have recognized the hype – or how financial, political, and other interests have boosted the circulation of (often) exaggerated claims. This means shifting the gaze from AI as an intellectual endeavor, to see AI as a market – where bubbles can, well, form. This also means recognizing the political dimensions of AI development, with many states using public funding as a crucial engine for innovation.
Second, AI practitioners engage in a form of social construction of morality to legitimate their approaches to AI. For example, some distance themselves from Big Tech capitalism, some insist on the benefits of some AI applications, most prominently in healthcare. These efforts ultimately shape which technologies gain visibility and attract capital investments. This is also a way through which they produce and sustain the AI bubble itself – a culturally embedded market phenomenon. Third, sociological analysis can move beyond the technological determinism of early AI critics to emphasize the social and institutional contexts within which such algorithmic decision-making systems are deployed. This brings to light forms of negotiation, adaptation, and resistance, which have more subtle effects on inequalities.
In sum, sociologists increasingly contribute to these conversations, although these topics are not prominent in the discipline’s flagship conferences and journals, and important knowledge gaps remain. The guest-editors of the forthcoming Social Science Computer Review special issue on “What is sociological about AI?” claim that “A sociological lens can render AI’s hidden processes legible, just as sociologists have done with complex and taken for granted social forces since the discipline’s inception”. They nevertheless note that “we neither have a robust concept of AI as a social phenomenon nor a holistic sociological discourse around it, despite vibrant and dynamic work in the area.” In passing, most extant studies rely on traditional methods, primarily surveys and fieldwork. This is not an issue in itself, but it highlights a disconnection with the sub-topic I’ll highlight in my next post – Sociology using AI as instrument.
How do digital platforms affect the concrete functioning of markets that pre-existed them? Platforms are intermediaries and it was initially thought that they could solve any mismatches between supply and demand. In the restaurant sector, the hope was that they would seamlessly connect diners with available tables and help restaurants fill their rooms. Yet traditional booking methods remain, and many restaurants restrict the number of seats offered through platforms. A recent study, which I have just co-published with Elise Penalva Icher and Fabien Eloire, examines why.
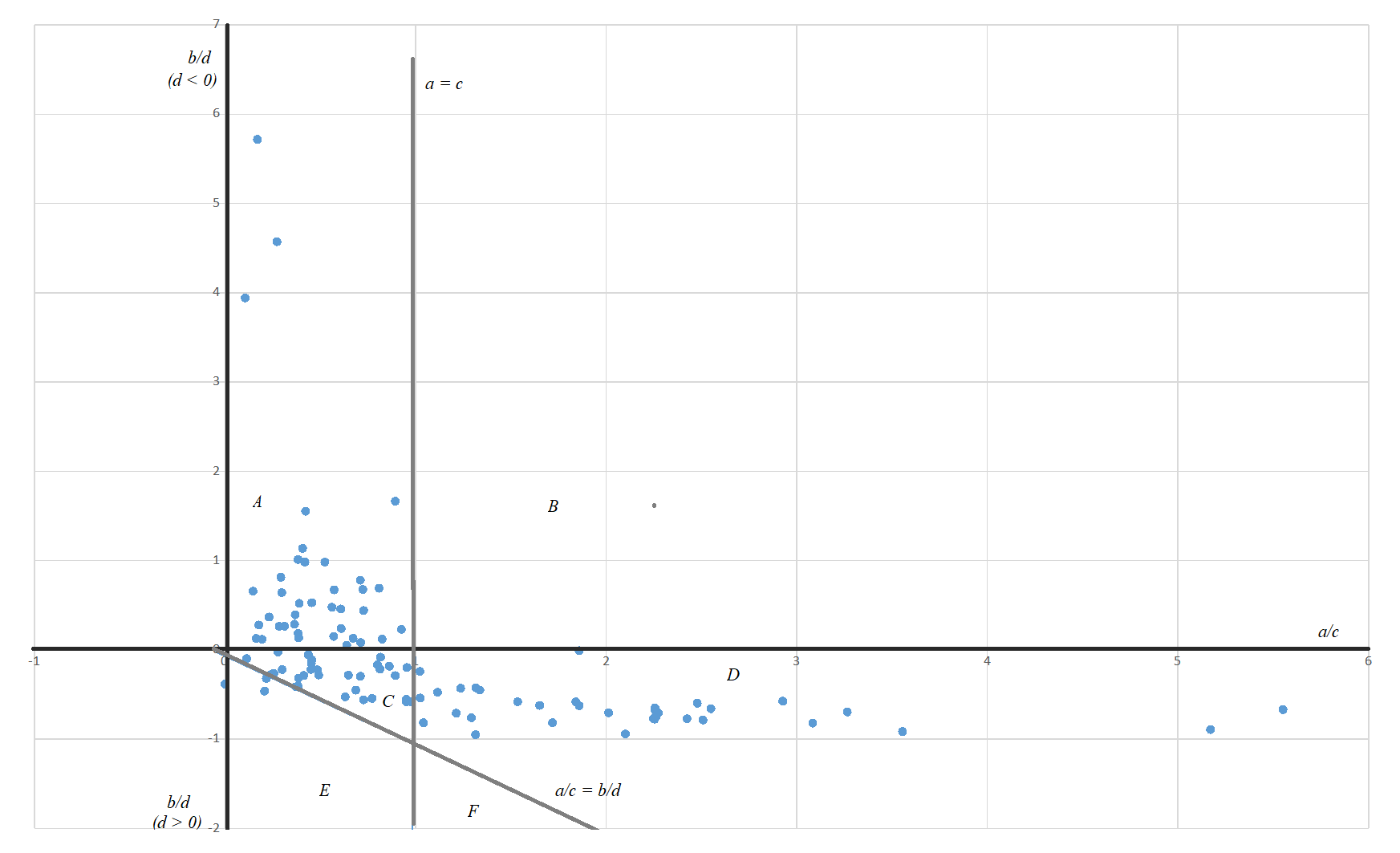
We borrow Harrison White’s famous producer market model, based on the idea that the key problem of a firm is to position itself in a market that consists of differentiated niches. Restaurants are not homogeneous, and they continuously scan the market to fine-tune their offer – from fine dining to bistro and pizzeria. They evaluate two main indicators: volume, which is relatively straightforward, and quality, which is harder to gauge as it depends on subjective customer perceptions. Platforms break through this limitation by publishing consumers’ reviews and aggregating them into ratings. They provide “digital glasses” that reveal quality alongside volume.
The study investigates dine-in services in Lille, France, in the case of a widely adopted booking and review platform. Methods include participant observation, interviews, web-scraping, and quantitative analysis of business data.
Lille restaurants in Harrison White’s model plot. Note:Horizontal axis: volume, vertical axis: quality. The sub-axes distinguish a non-viable (“Failure”) region from a viable one, in turn subdivided into three different regions (“Ordinary”, “Advanced” and “Paradox”). Zone A = Paradox, zone C = Ordinary, zone D = Advanced, all other zones = Failure. N = 105.
Findings highlight three key effects. First, an amplification effect: platforms enable restaurants to see “like a market,” not just through their own customers but also through competitors’ clients. Second, a normalization effect: platform use pushes firms to standardize their offers, fostering similarity without complete homogenization. Third, a duration effect: sustained platform participation depends on quality positioning, although many restaurants exit after a few years, partly in response to platform dominance. These dynamics suggest a broader rationalization process in which platforms make market observation more systematic and efficient.
This perspective nuances common claims about platforms as market “revolutions.” The study finds no evidence that platforms improve consumer–producer matching. None of the interviewed restaurateurs feared empty tables, and some deliberately withheld capacity from the platform to accommodate walk-ins or phone bookings. Overemphasizing intermediation, earlier research may have overlooked subtler effects. The key function of platforms does not always have to be matching. They can play diverse and even unbalanced roles on a single side of the market, without striving toward a competitive supply-demand equilibrium.
The analysis also reaffirms the validity of White’s model. Originally designed for settings where firms observed only volumes, the model still applies when platforms disclose quality through reviews. Its insights hold across different technological contexts.
Finally, the study underscores the limits of using platforms as sources of research data. We relied on platform data, but we faced gaps: available data are partial because platform objectives differ from research needs, and algorithms remain proprietary. This raises concerns, as platforms exert broad societal influence while controlling critical information.
Overall, the research advances understanding of how platforms affect business practices, in this case restaurants. It contributes to critical scholarship that recognizes the novelty of platform intermediation while tempering claims about its benefits.
When we created ENDL (the European Network on Digital Labour), back in 2017, we booked a room with 17 places. A few days ago, the last conference of the network (which in the meantime has become INDL, replacing ‘European’ with ‘International’) hosted about 200 participants. Internationalisation has not only meant numerical growth, but also inclusion of a diverse range of voices: every year, we see more participants from countries that are often under-represented on the scientific scene, from India and South Africa to Argentina and Brazil. Participants have also diversified in another sense, too: if the majority have always been academics, it is a pleasure to see more and more workers, as well as labour organisers. This year, we could for example benefit from the presence of associations of data workers from Kenya, freelancers from France, and content moderators from Spain.
Participants to the INDL-8 conference, Saint-Cristina cloister, Bologna, IT, 10 September 2025.
A conference like this one is meant to give hope – hope of mutual understanding across countries and cultures, hope of dialogue across disciplines and fields, hope of connections between academic research and action. We worked together to ensure a welcoming environment for all, for instance by encouraging constructive comments, rather than sheer criticism, after each paper presentation. We also strived to keep costs down in order to make the conference free of charge, and with the DiPLab research programme, we could give a few small scholarships to promising presenters who might not have been able to travel otherwise.
Two speakers (M Francesco Sinopoli, Fondazione Di Vittorio, and Ms Kauna Malgwi, Uniglobal) at the plenary panel ‘Plenary panel: New Unionism, towards global alliances’, part of the INDL-8 Conference, DAMA Tecnopolo, Bologna, IT, 11 September 2025
Surely, problems remain. A couple potential participants had visa issues, while others had to cancel due to lack of funding. These problems weigh especially hard on people from emerging and lower-income countries outside Europe and North America. The future is also uncertain, as funding sources become increasingly dryer, and visa restrictions tighter. For this reason, the main INDL-9 conference next year (Geneva, ILO, 9-11 September 2026) will be accompanied by the growth of local chapters. The Middle-East and Africa area is preparing its second conference, this time online only, on 25-26 November. In the US, a one-day event will take place at Yale University on 29 April 2026. Colleagues in Chile and Argentina are launching a series of online events.
Closing keynote (Prof. Sandro Mezzadra, chair: Prof. Marco Marrone), Saint-Cristina Aula Magna, Bologna, IT, 12 September 2025
More information on the INDL-8 conference (including the full programme) is available here.
I presented today, at the WORK2025 conference in Turku, Finland, a paper on the human-in-the-loop systems that integrate human labor into the production of Artificial Intelligence (AI). Beyond engineers who design models, myriad “data workers” prepare training data, verify outputs, and correct errors. Their role is crucial but undervalued, with low pay and poor working conditions. Shaped by outsourcing and offshoring practices, the market for such services has grown steadily over time, with digital platforms acting as the main intermediaries between AI producers and workers. In their communication with clients, these platforms often emphasize that human workers provide nuanced judgment in complex tasks.
The three main functions of micro-work in the development of data-intensive, machine-learning based AI solutions. Source: https://doi.org/10.1177/2053951720919776
But who are the humans in the loop, and whose contributions count? Here, I focus on women’s participation and its evolution as the market expanded. Data work is theoretically well-suited for women, since it can be performed remotely from home. Besides, platforms generally do not share gender information, thereby limiting direct discrimination. One might thus expect women’s representation to be high. However, the statistical evidence is mixed. Across studies, the proportion of women data workers exceeds 50% only in four cases. Besides, reports sometimes differ for the same country, across platforms or at different moments in time. Looking at the lowest reported shares, then in no country except the US do women represent more than 40% of all data workers. Even in the US, recent data indicate that women constitute about half of the data workforce, down from 57-58% some years ago. Why are women underrepresented, and why does the pattern vary across countries?
Highest proportion of women data workers reported in existing studies (incl. own datasets). Source: author’s elaboration, created with MapChart.Lowest proportion of women data workers reported in existing studies (incl. own datasets). Source: author’s elaboration, created with MapChart.
The earliest explanation comes from P. Ipeirotis (2010), who analyzed Amazon Mechanical Turk, then the dominant platform. Most workers were from the US and India. In the US, data work paid too little to sustain a household and was often taken up by un- and under-employed women seeking supplementary income. In India, dollar-based pay was more attractive and often a main household income, drawing more men into the activity. Later, as the market expanded, this explanation appeared insufficient: the above maps show that not all rich countries have many female data workers, and some lower-income countries do. Yet, my data show a negative correlation: the larger the share of workers for whom data work is the main income source, the smaller the proportion of women. Ipeirotis’s hypothesis still holds but requires updating to today’s more competitive and globalized platform economy.
Proportion of workers for whom data work is the main source of income vs. proportion of women, by country. Source: own survey data (from projects TRIA and ENCORE, 2020-24).
Platforms fragment work into tasks and assign them to individuals framed as independent contractors competing for access. Unlike traditional firms, workers do not collaborate but face intense competition. Outcomes vary by national context. In countries facing stagnation or crisis, such as Venezuela, international platforms offer a rare source of income for highly qualified workers. Competition becomes fierce, and “elite” workers – often young men with STEM backgrounds – dominate. Women are disadvantaged, either due to fewer technical qualifications or because care responsibilities limit their ability to invest in building strong platform profiles and reputations. By contrast, in more dynamic economies such as Brazil, local job markets absorb highly skilled professionals, leaving platform work to more disadvantaged groups. Here, women with family duties are more visible. Thus, platform demographics reflect national conditions: in poorer or crisis-stricken countries, men from the educational elite seek career advancement, while in richer countries, women (especially mothers) take on such work primarily to supplement household income. Women may be equally educated, but they often lack the time to cultivate advanced STEM skills. As platforms demand longer and more specialized tasks, men increasingly gain the upper hand, crowding women out—even in countries where they were once the majority.
Platform design ignores these dynamics. Workers are treated as abstract entities, stripped of the socio-economic and cultural contexts that shape real inequalities. Competition, combined with local conditions, deepens gender gaps. Interventions must therefore consider gender disparities. Otherwise, they risk reinforcing inequalities. Supporting women’s access to data work—particularly those constrained by family responsibilities—can contribute to more balanced labor participation and ensure that AI benefits from a broader diversity of human input.
Within the Horizon-Europe project AI4TRUST, we published a first report presenting the state of the art in the socio-contextual basis for disinformation, relying on a broad review of extant literature, of which the below is a synthesis.
What is disinformation?
Recent literature distinguishes three forms:
‘misinformation’ (inaccurate information unwittingly produced or reproduced)
‘disinformation’ (erroneous, fabricated, or misleading information that is intentionally shared and may cause individual or social harm)
‘malinformation’ (accurate information deliberately misused with malicious or harmful intent).
Two consequences derive from this insight. First, the expression ‘fake news’ is unhelpful: problematic contents are not just news, and are not always false. Second, research efforts limited to identifying incorrect information alone, without capturing intent, may miss some of the key social processes surrounding the emergence and spread of problematic contents.
How does mis/dis/malinformation spread?
Recent literature often describes the characteristics of the process of diffusion of mis/dis/malinformation in terms of ‘cascades’, that is, the iterative propagation of content from one actor to others in a tree-like fashion, sometimes with consideration of temporality and geographical reach. There is evidence that network structures may facilitate or hinder propagation, regardless of the characteristics of individuals: therefore, relationships and interactions constitute an essential object of study to understand how problematic contents spread. Instead, the actual offline impact of online disinformation (for example, the extent to which online campaigns may have inflected electoral outcomes) is disputed. Likewise, evidence on the capacity of mis/dis/malinformation to spread across countries is mixed. A promising perspective to move forwards relies on hybrid approaches mixing network and content analysis (‘socio-semantic networks’).
What incentivizes mis/dis/malinformation?
Mis/dis/malinformation campaigns are not always driven solely by political tensions and may also be the product of economic interest. There may be incentives to produce or share problematic information, insofar as the business model of the internet confers value upon contents that attract attention, regardless of their veracity or quality. A growing, shadow market of paid ‘like’, ‘share’ and ‘follow’ inflates the rankings and reputation scores of web pages and social media profiles, and it may ultimately mislead search engines. Thus, online metrics derived from users’ ratings should be interpreted with caution. Research should also be mindful that high-profile disinformation campaigns are only the tip of the iceberg, low-stake cases being far more frequent and difficult to detect.
Who spreads mis/dis/malinformation?
Spreaders of mis/dis/malinformation may be bots or human users, the former being increasingly controlled by social media companies. Not all humans are equally likely to play this role, though, and the literature highlights ‘super-spreaders’, particularly successful at sharing popular albeit implausible contents, and clusters of spreaders – both detectable in data with social network analysis techniques.
How is mis/dis/malinformation adopted?
Adoption of mis/dis/malinformation should not be taken for granted and depends on cognitive and psychological factors at individual and group levels, as well as on network structures. Actors use ‘appropriateness judgments’ to give meaning to information and elaborate it interactively with their networks. Judgments depend on people’s identification to reference groups, recognition of authorities, and alignment with priority norms. Adoption can thus be hypothesised to increase when judgments are similar and signalled as such in communication networks. Future research could target such signals to help users in their contextualization and interpretation of the phenomena described.
Multiple examples of research in social network analysis can help develop a model of the emergence and development of appropriateness judgements. Homophily and social influence theories help conceptualise the role of inter-individual similarities, the dynamics of diffusion in networks sheds light on temporal patterns, and analyses of heterogeneous networks illuminate our understanding of interactions. Overall, social network analysis combined with content analysis can help research identify indicators of coordinated malicious behaviour, either structural or dynamic.
We examine the implications of the use of digital micro-working platforms for scientific research. Although these platforms offer ways to make a living or to earn extra income, micro-workers lack fundamental labour rights and ‘decent’ working conditions, especially in the Global South. We argue that scientific research currently fails to treat micro-workers in the same way as in-person human participants, producing de facto a double morality: one applied to people with rights acknowledged by states and international bodies (e.g. Helsinki Declaration), the other to ‘guest workers of digital autocracies’ who have almost no rights at all.