With our sponsors France Stratégie and MSH Paris-Saclay, we convene an international conference on micro-work in Paris on June 13, 2019, followed by the first INDL (International Network on Digital Labor) workshop on June 14. The event will include a “meet the microworkers” panel on June 13, where workers, platform owners and client companies will take the stage. There will also be presentations of the results of national and international surveys (notably ours, DiPLab) on these emerging forms of work, and discussions with French and international academic and institutional experts.
After Uber, Deliveroo and other on-demand services, micro-work is a new form of labor mediated by digital platforms. Internet and mobile services recruit crowds to perform small, standardized and repetitive tasks on behalf of corporate clients, in return for fees ranging from few cents to few euros. These tasks generally require low skills: taking a picture in a store, recognizing and classifying images, transcribing bits of text, formatting an electronic file… Despite their apparent simplicity, these micro-tasks performed by millions of people around the world, are crucial to create the databases needed to calibrate and “train” artificial intelligence algorithms.
Internationally, Amazon Mechanical Turk is the most widely known micro-work platform. In France and in French-speaking Africa, other platforms are attracting a growing number of workers to supplement or even substitute for their primary income. How widespread is the phenomenon? How to recognize, organize and regulate this new form of work? How, finally, does it relate to traditional forms of employment?
Presentations and discussions are held in French and English, with simultaneous translation.
Table ronde, Sciences Po Paris, 6 décembre 2018, 18h00
Pour que la recherche en sciences sociales puisse pleinement tirer profit des grandes bases de données numériques, un verrou reste à lever : l’accès à ces données est limité, inégalement distribué, et entouré d’un flou juridique et déontologique. Nous proposons d’en discuter à l’occasion de la parution du numéro spécial de la Revue Française de Sociologie sur “Big data, sociétés et sciences sociales” (n. 59/3). Cette table ronde réunit les chercheur.e.s avec d’autres parties prenantes publiques et
privées.
Avec :
Garance Lefèvre, Policy senior associate, Uber
Roxane Silberman, Conseillère scientifique, Centre d’Accès Sécurisé aux Données (CASD)
Sophie Vulliet-Tavernier, Directrice des relations avec les publics et la recherche, Commission Nationale de l’Informatique et des Libertés (CNIL)
Les auteurs du numéro spécial.
Modérateurs : Gilles Bastin (Univ. Grenoble Alpes) et Paola Tubaro (CNRS), coordinateurs du numéro spécial.
Entrée libre et gratuite, dans la limite des places disponibles: pour s’inscrire, cliquez ici.
Accès : Sciences Po, salle Goguel. Entrée par le 27 rue Saint-Guillaume, 75007 Paris (traverser le jardin et prendre l’ascenseur jusqu’au dernier étage). La table ronde est organisée par la Revue Française de Sociologie en collaboration avec les Presses de Sciences Po. Elle sera suivie d’un pot.
I was last week at the second Reshaping Work in the Platform Economy in Amsterdam. The interest of this small conference is tht it brings together different actors of the platform economy, from academics and students to policymakers, union leaders, workers, and representatives of platforms to discuss.
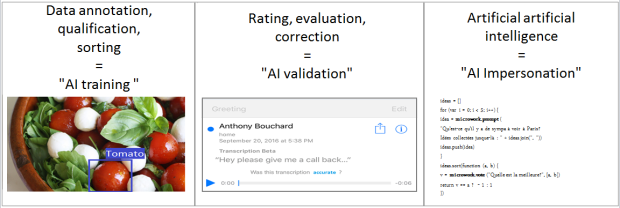
In an overview of preliminary results of our project DiPLab, Antonio A. Casilli and I presented our reflection on how micro-work powers artificial intelligence (AI), in three main ways:
Training AI
Validating outcomes of AI
Impersonating AI when it is cheaper or simpler that real AI
No more details for now… it will come out as a working paper very soon!
Just came back from the Work, Employment and Society (WES) conference 2018, that British Sociological Association (BSA) organizes every other year. Perhaps more intimate and newbie-friendly than the main BSA event, this year’s WES in Belfast was also a positive surprise in terms of its academic content. There were several sessions on the so-called ‘gig economy’ (or as one speaker put it, ‘gig economies‘), the effects of digital business models that often go under the name of ‘uberization’, and atypical forms of work.
Some lessons I am taking home:
A growing number of researchers are studying platform work – not just the most visible forms of it such as Uber drivers and Deliveroo couriers, but also those who are hidden at home: freelancers and to a lesser extent, micro-workers;
The question of how platform workers self-organize, and what can be done to improve their organization capacity, is attracting a lot of attention;
Efforts at establishing standards, fairness criteria and forms of social protection for atypical platform workers are gaining momentum;
There is a lot we can learn from research in neighboring areas: for example the distinction between employee-friendly and employer-friendly flexible work, initially developed for people in employment, is also helpful here.
What is still missing from the picture is information on the ‘long tail’ of smaller, often national rather than international, platforms, and on the workers (especially micro-workers) who use them. Besides, clients and requesters are little known – on all platforms. Estimating the size of the platform worker population remains an unresolved issue – whether at local, national or international level. A common grievance by researchers is difficulty to access crucial data from commercial platforms that use them as their private property.
Research on social networks raises formidable ethical issues that often fall outside existing regulations and guidelines. State-of-the-art tools to collect, handle, and store personal data expose both researchers and participants to new risks. Political, military and corporate interests interfere with scientific priorities and practices, while legal and social ramifications of studies of personal ties and human networks come to the surface.
The proposed special section aims to critically engage with ethics in research related to social networks, specifically addressing the challenges that recent technological, scientific, legal and political transformations trigger.
Following a successful workshop on this topic that was held in December 2017 in Paris, we welcome submissions that critically engage with ethics in research related to social networks, possibly based on reflective accounts of first-hand experiences or case studies, taken as concrete illustrations of the general principles at stake, the attitudes and behaviors of stakeholders, or the legal and institutional constraints. We are particularly interested in novel, original answers to some unprecedented ethical challenges, or the need to reinterpret norms in ambiguous situations.
Fueled by increasingly powerful computing and visualization tools, research on social networks is flourishing. However, it raises ethical issues that largely escape existing codes of conduct and regulatory frameworks. The economic power of large data platforms, the active participation of network members, the spectrum of mass surveillance, the effects of networking on health, the place of artificial intelligence: so many questions in search of solutions.
Social networks, what are we talking about?
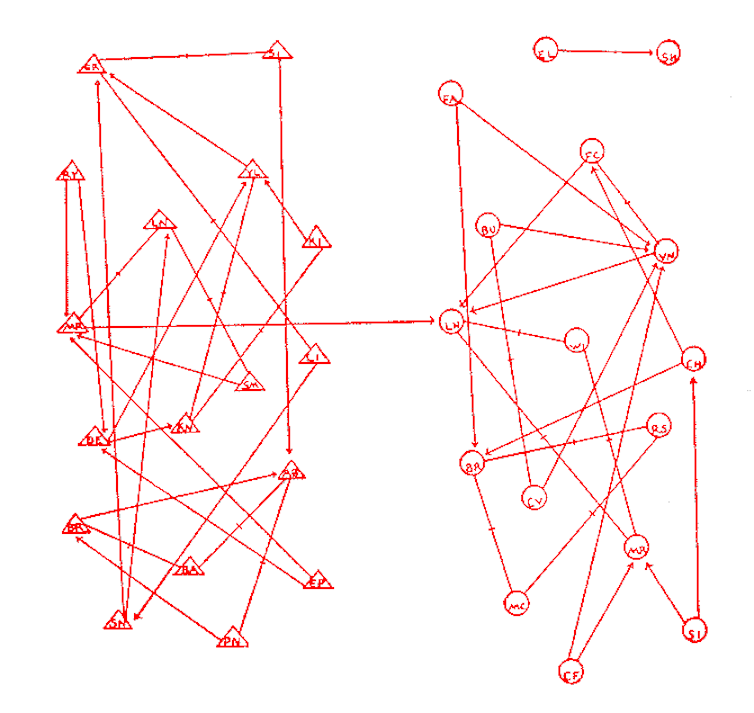
The expression “social network” has become common, but those who use it to refer to social media as Facebook or Instagram often ignore its origin and its true meaning. The study of social networks precedes the advent of digital technologies. Since the 1930s, sociologists have been conducting surveys to describe the structures of relationships that unite individuals and groups: their “networks”. These include, for example, advice relationships between employees of a company, or friendship ties between students in a school. These networks can be represented as points (students) united by lines (links).
Figure 1 : a social network of friendship ties between students in a school. Circles = girls, triangles = boys, arrows = ties. J.L. Moreno, Who shall survive? 1934.
Before any questioning on the social aspects of Facebook and Twitter, this research shed light on, for example, marital role segregation, importance of “weak ties” in job search, informal organization of firms, diffusion of innovations, formation of business elites, social support for the sick or elderly. Designers of digital platforms such as Facebook have picked up some of the analytical principles on which these works were based, developing them with the mathematical theory of graphs (though often with less attention to the social issues involved).
Early on, researchers in this field realized that the traditional principles of research ethics (focusing on informed consent of study participants and anonymization of data) were difficult to ensure. By definition, social networks research is never about a single individual, but about relationships between this individual and others – their friends, relatives, collaborators or professional advisors. If the latter are reported by the respondent but are not themselves included in the study, it is difficult to see how their consent could be obtained. What’s more, results can be difficult to anonymize, in that visuals are sometimes disclosive even in the absence of personal identifiers.
Ethics in the digital society: a minefield
Academics have long been thinking about these ethical difficulties, to which a special issue of the prestigious Social Networks journal was dedicated as far back as 2005. Today, researchers’ dilemmas are exacerbated by the increased availability of relational data collected and exploited by digital giants like Facebook or Google. New problems arise as the boundaries between “public” and “private” spheres become confused. To what extent do we need consent to access messages that digital service users send to their contacts, their “retweets”, or their “likes” on their friends’ walls?
These sources of information are often the property of commercial enterprises, and the algorithms they use likely bias observations. For example, can we interpret in the same way a contact created spontaneously by a user, and a contact created as a result of an automated recommendation system? In short, the data do not speak for themselves, and before thinking about their analysis, we must question the conditions of their use and the methods of their production. They largely depend on the software architectures imposed by platforms as well as their economic and technical choices. There is a real power asymmetry between platforms – often the property of large multinational companies – and researchers – especially those working in the public sector, and whose objectives are misaligned with investors’ priorities. Negotiations (if possible at all) are often difficult, resulting in restrictions to proprietary data access – particularly penalizing for public research.
Other problems arise as a researcher may even use paid crowdsourcing to produce data, using platforms like Amazon Mechanical Turk to ask large numbers of users to complete a questionnaire, or even to download their online contact lists. But these services raise numerous questions in terms of workers’ rights, working conditions and appropriation of the product of work. The resulting uncertainty hinders research that could otherwise have a positive impact on knowledge and on society at large.
Availability of online communication and publication tools, which many researchers are now seizing, increases the likelihood that research results may be diverted for political or business purposes. If the interest of military and police circles for the analysis of social networks is well known (Osama Bin Laden was allegedly located and neutralised following the application of social network analysis principles), these appropriations are more frequent today, and less easily controllable by researchers. A significant risk is the use of these principles to suppress civic and democratic movements.
Restrictions and prohibitions would likely aggravate the constraints that already weigh on researchers, without helping them overcome these obstacles. Rather, it is important to create conditions for trust and enable researchers to explore the full extent and importance of online and offline social networks – allowing them to capture salient economic and social phenomena while remaining respectful of people’s rights. Researchers should take an active role, participating in the co-construction of an adequate ethical framework, grounded in their experience and self-reflective attitude. A bottom-up process involving academics as well as citizens, civil society associations, and representatives of public and private research organizations could then feed these ideas and thoughts back to regulators (such as ethics committees).
With a group of colleagues from Universitat Autònoma de Barcelona and in Collaboration with OuiShare, we are studying networking at the event. The OuiShare Fest aims, among other things, to bring people together: we want to see how interactions between participants facilitate circulation of ideas and possibly give rise to future collaborations.
Research on social networks is experiencing unprecedented growth, fuelled by the consolidation of network science and the increasing availability of data from digital networking platforms. However, it raises formidable ethical issues that often fall outside existing regulations and guidelines. New tools to collect, treat, store personal data expose both researchers and participants to specific risks. Political use and business capture of scientific results transcend standard research concerns. Legal and social ramifications of studies on personal ties and human networks surface.
We invite contributions from researchers in the social sciences, economics, management, statistics, computer science, law and philosophy, as well as other stakeholders to advance the ethical reflection in the face of new research challenges.
The workshop will take place on 5 December 2017 (full day) at MSH Paris-Saclay, with open keynote sessions to be held on 6 December 2017 (morning) at Hôtel de Lauzun, a 17th century palace in the heart of historic Île de la Cité.
Let us know if you wish to be panel discussant or session chair by 20 October 2017 (send to: recsna17@msh-paris-saclay.fr).
Acceptance notifications will be sent by 31 October 2017.
Registration is free but mandatory: speakers (and discussants and chairs) should register between 15 October and 15 November 2017, other attendees by 30 November 2017.
Keynote Speakers
José Luis Molina, Autonomous University of Barcelona, “HyperEthics: A Critical Account” Bernie Hogan, Oxford Internet Institute, “Privatising the personal network: Ethical challenges for social network site research”
Scientific Committee
Antonio A. Casilli (Telecom ParisTech, FR), Alessio D’Angelo (Middlesex University, UK), Guillaume Favre (University of Toulouse Jean-Jaurès, FR), Bernie Hogan (Oxford Internet Institute, UK), Elise Penalva-Icher (University of Paris Dauphine, FR), Louise Ryan (University of Sheffield, UK), Paola Tubaro (CNRS, FR).
The OuiShare Fest brings together representatives of the international collaborative economy community. One of its goals is to expose participants to inspiring new ideas, while also offering them an opportunity for networking and building collaborative ties.
At the 2016 OuiShare Fest, we ran a study of people’s networking. Attendees, speakers and team members were asked to complete a brief questionnaire, on paper or online.Through this questionnaire, we gained information on the relationships of 445 persons – about one-third of participants.
Ties that separate: the inheritance of past relationships
For many participants, the Fest was an opportunity to catch up with others they knew before. Of these relations, half are 12 months old at most. About 40% of them were formed at work; 15% at previous OuiShare Fests or other collaborative economy experiences; 9% can be ascribed to living in the same town or neighborhood; and 7% date back to school time.
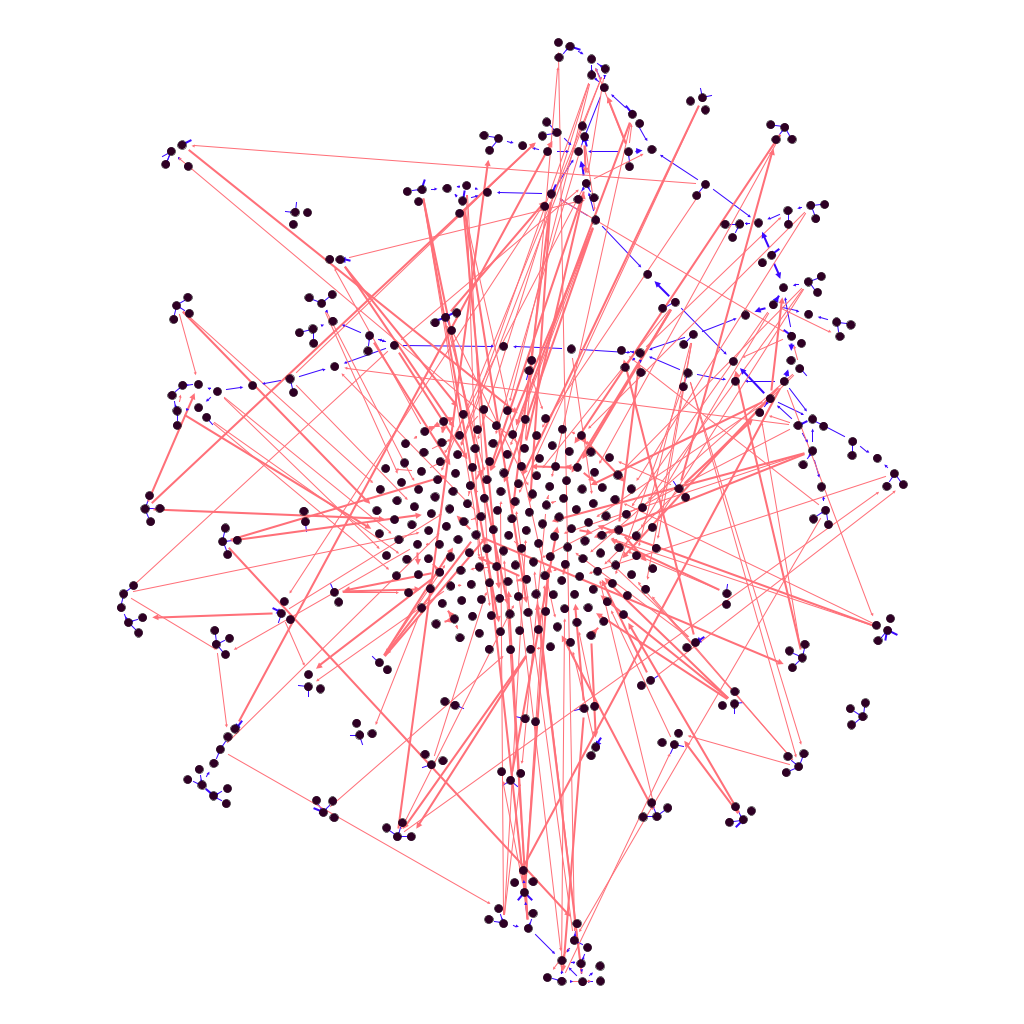
Figure 1: pre-existing ties
Figure 1 is a synthesis of these “catching-up-with-old-friends” relationships, in the shape of a network where small black dots represent people and blue lines represent social ties between them. At the center of the graph are “isolates”, participants who had no pre-existing relationship among OuiShare Fest attendees. The remaining 60% have prior connections, but form part of separate clusters. Some of them (27%) form a rather large component, visible at the top of the figure, where each member is directly or indirectly connected to anyone else in that component. There are also two medium-sized clusters of connected people at the bottom. The rest consists of many tiny sub-groups, mostly of 2-3 individuals each.
Ties that bind: new acquaintances made at the event
Participants told us that they also met new persons at the Fest. Figure 2 enriches Figure 1 by adding – in red – the new connections that people made during the event. The ties formed during the Fest connect the clusters that were separate before: now, 86% of participants are in the largest network component, meaning that any one of them can reach, directly or indirectly, 86% of the others.




 Just came back from the
Just came back from the