Research on social networks raises formidable ethical issues that often fall outside existing regulations and guidelines. State-of-the-art tools to collect, handle, and store personal data expose both researchers and participants to new risks. Political, military and corporate interests interfere with scientific priorities and practices, while legal and social ramifications of studies of personal ties and human networks come to the surface.
The proposed special section aims to critically engage with ethics in research related to social networks, specifically addressing the challenges that recent technological, scientific, legal and political transformations trigger.
Following a successful workshop on this topic that was held in December 2017 in Paris, we welcome submissions that critically engage with ethics in research related to social networks, possibly based on reflective accounts of first-hand experiences or case studies, taken as concrete illustrations of the general principles at stake, the attitudes and behaviors of stakeholders, or the legal and institutional constraints. We are particularly interested in novel, original answers to some unprecedented ethical challenges, or the need to reinterpret norms in ambiguous situations.
Fueled by increasingly powerful computing and visualization tools, research on social networks is flourishing. However, it raises ethical issues that largely escape existing codes of conduct and regulatory frameworks. The economic power of large data platforms, the active participation of network members, the spectrum of mass surveillance, the effects of networking on health, the place of artificial intelligence: so many questions in search of solutions.
Social networks, what are we talking about?
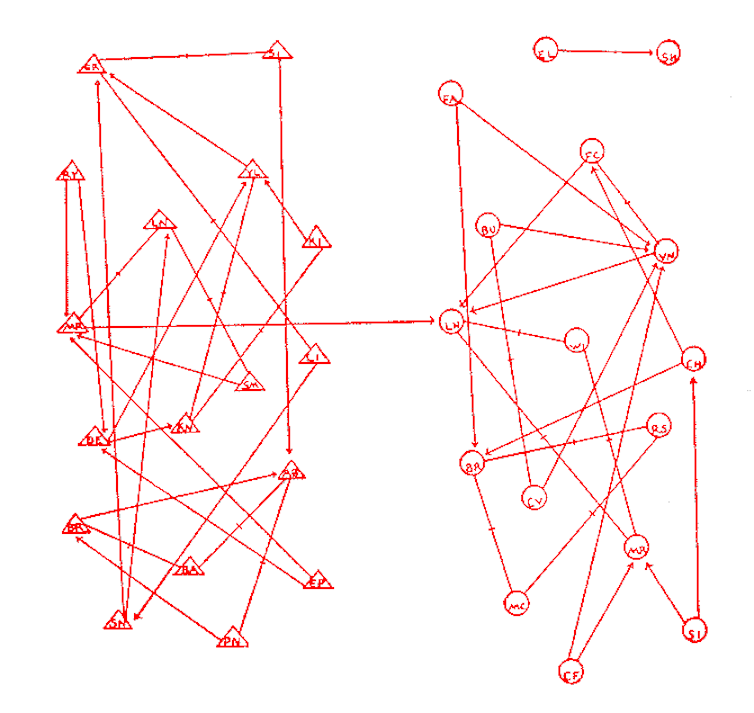
The expression “social network” has become common, but those who use it to refer to social media as Facebook or Instagram often ignore its origin and its true meaning. The study of social networks precedes the advent of digital technologies. Since the 1930s, sociologists have been conducting surveys to describe the structures of relationships that unite individuals and groups: their “networks”. These include, for example, advice relationships between employees of a company, or friendship ties between students in a school. These networks can be represented as points (students) united by lines (links).
Figure 1 : a social network of friendship ties between students in a school. Circles = girls, triangles = boys, arrows = ties. J.L. Moreno, Who shall survive? 1934.
Before any questioning on the social aspects of Facebook and Twitter, this research shed light on, for example, marital role segregation, importance of “weak ties” in job search, informal organization of firms, diffusion of innovations, formation of business elites, social support for the sick or elderly. Designers of digital platforms such as Facebook have picked up some of the analytical principles on which these works were based, developing them with the mathematical theory of graphs (though often with less attention to the social issues involved).
Early on, researchers in this field realized that the traditional principles of research ethics (focusing on informed consent of study participants and anonymization of data) were difficult to ensure. By definition, social networks research is never about a single individual, but about relationships between this individual and others – their friends, relatives, collaborators or professional advisors. If the latter are reported by the respondent but are not themselves included in the study, it is difficult to see how their consent could be obtained. What’s more, results can be difficult to anonymize, in that visuals are sometimes disclosive even in the absence of personal identifiers.
Ethics in the digital society: a minefield
Academics have long been thinking about these ethical difficulties, to which a special issue of the prestigious Social Networks journal was dedicated as far back as 2005. Today, researchers’ dilemmas are exacerbated by the increased availability of relational data collected and exploited by digital giants like Facebook or Google. New problems arise as the boundaries between “public” and “private” spheres become confused. To what extent do we need consent to access messages that digital service users send to their contacts, their “retweets”, or their “likes” on their friends’ walls?
These sources of information are often the property of commercial enterprises, and the algorithms they use likely bias observations. For example, can we interpret in the same way a contact created spontaneously by a user, and a contact created as a result of an automated recommendation system? In short, the data do not speak for themselves, and before thinking about their analysis, we must question the conditions of their use and the methods of their production. They largely depend on the software architectures imposed by platforms as well as their economic and technical choices. There is a real power asymmetry between platforms – often the property of large multinational companies – and researchers – especially those working in the public sector, and whose objectives are misaligned with investors’ priorities. Negotiations (if possible at all) are often difficult, resulting in restrictions to proprietary data access – particularly penalizing for public research.
Other problems arise as a researcher may even use paid crowdsourcing to produce data, using platforms like Amazon Mechanical Turk to ask large numbers of users to complete a questionnaire, or even to download their online contact lists. But these services raise numerous questions in terms of workers’ rights, working conditions and appropriation of the product of work. The resulting uncertainty hinders research that could otherwise have a positive impact on knowledge and on society at large.
Availability of online communication and publication tools, which many researchers are now seizing, increases the likelihood that research results may be diverted for political or business purposes. If the interest of military and police circles for the analysis of social networks is well known (Osama Bin Laden was allegedly located and neutralised following the application of social network analysis principles), these appropriations are more frequent today, and less easily controllable by researchers. A significant risk is the use of these principles to suppress civic and democratic movements.
Restrictions and prohibitions would likely aggravate the constraints that already weigh on researchers, without helping them overcome these obstacles. Rather, it is important to create conditions for trust and enable researchers to explore the full extent and importance of online and offline social networks – allowing them to capture salient economic and social phenomena while remaining respectful of people’s rights. Researchers should take an active role, participating in the co-construction of an adequate ethical framework, grounded in their experience and self-reflective attitude. A bottom-up process involving academics as well as citizens, civil society associations, and representatives of public and private research organizations could then feed these ideas and thoughts back to regulators (such as ethics committees).
Some time ago, I wrote a post on ethical issues in research with secondary data – a somewhat grey area, where students and scholars often feel guidance is insufficient. Even more complex is research with internet data – neither primary nor secondary strictly speaking, but “big” data. A recent case fuelled an international debate on how researchers should deal with data that are, apparently, accessible to all on the web: a Danish graduate student published a large dataset of users of the online dating site OkCupid (he apparently did so without any institutional backing, and Aarhus University where he studies, is now on the case). Michael Zimmer, a specialist of information studies and the policy and ethics of online research, properly summarizes the issues in a recent Wired article:
Don’t say that “the data are already public”. The fact that OkCupid users knowingly share some personal information, does not mean they consent to it being used for purposes other than interactions with other users on that site. By scrapping data, one may be able to put together the whole history of users’ presence on that platform, revealing more of their life or personality than they themselves are aware of. More dangerously, data extracted in this way might in some cases be matched with other information, thereby potentially becoming much more disclosive than what the persons concerned ever intended or agreed. And the disclosure may be aggravated by releasing the data outside the platform.
A major health data plan is on the verge of being called off, to never have a chance again. It is supposed to anonymise all the patient records in the National Health Service (NHS) in the UK, linking them together into one single, giant database, and making them available under controlled use conditions to health researchers and (controversially) to commercial companies too. Public outcry has led to the plan being delayed for six months.
In an article published in The Guardian last week, Ben Goldacre, a medical doctor and high-profile media commentator on science matters, rightly identifies what the point is: in principle, the public accepts release of data for scientific purposes, but resists commercial exploitation. And rightly so: medical knowledge results from the study of several cases, and the higher the availability of cases, the more accurate the results; in the era of big data, it is also clear that aggregation and sharing of a wealth of data such as those held by the NHS is a unique opportunity for medical science to discover ways of saving lives. On the other hand, use of data for any other purposes looks much more opaque, and people understandably feel it might lead to discrimination and potentially negative individual consequences, for example if disclosure of the health history of a person results in higher insurance premiums, or rejection of job applications.
Our new book Against the Hypothesis of the End of Privacy is out now! It has been published by Springer and co-authored with Antonio A. Casilli (Telecom ParisTech) and Yasaman Sarabi (University of Greenwich). Please check here for regular updates about the book.
If you are a researcher in economics, demography, sociology, geography or political science, you may have experienced the frustration of discovering a relevant data resource and being denied access to it — typically on the ground that data release would violate the confidentiality of data subjects. Or you may have heard of fantastic analyses — with all the fancy new statistical and econometrics tools and software that are increasingly in fashion today — done with large amounts of very detailed microdata, but you have no clue how to do anything like that yourself. Maybe you have tried to look at the website of some public administration that likely holds the data you want – like labor market or business data — but could not figure out how to ask for these data in the first place. And f you ever tried to access data from two or more different countries, you probably found the task of even finding out how to apply in different systems daunting.
Now, there is a great opportunity for you to get closer to your goal. The European project “Data without Boundaries” (DwB) offers social scientists from across Europe funding, information and support to access household surveys and business data from public-sector records in special Research Data Centers in France, Germany, the Netherlands and UK. These are microdata at individual level, highly detailed; they cannot be publicly released, but access can be legally given for scientific and statistical research purposes.
Both confirmed researchers and PhD students are welcome to apply, and should do so in a country different from the one where they reside. There is a preference for comparative, cross-country projects. The deadline is 15th October 2013.
This is part of a broader policy effort to improve researchers’ access to data in Europe, to enhance capacity to produce science-based understanding of society across the continent.
The “open data” movement is radically transforming policy-making. In the name of transparency and openness the UK, US and other governments are releasing large amounts of records. It is a way to hold the government to account: in UK for example, all lobbying efforts in the form of meetings with senior officers are now publicly released. Data also enable the public to make more informed decisions: for example, using apps from public transport services to plan their journeys, or tracking indicators of, say, crime or air pollution levels in their area to decide where to buy property. Data are provided as a free resource for all, and businesses may use them for profit.
The open data movement is not limited to the censuses and surveys produced by National Statistical Institutes (NSIs), the public-sector bodies traditionally in charge of collecting, storing and analyzing data for policy purposes. It extends to other administrations such as the Department for Work and Pensions or the Department for Education in the UK, which also gather and process data, though usually through a different process, not using questionnaires but rather registers.