
civilservicelocal/Pixabay
Antonio A. Casilli, Télécom ParisTech – Institut Mines-Télécom, Université Paris-Saclay et Paola Tubaro, Centre national de la recherche scientifique (CNRS)
Fueled by increasingly powerful computing and visualization tools, research on social networks is flourishing. However, it raises ethical issues that largely escape existing codes of conduct and regulatory frameworks. The economic power of large data platforms, the active participation of network members, the spectrum of mass surveillance, the effects of networking on health, the place of artificial intelligence: so many questions in search of solutions.
Social networks, what are we talking about?
The expression “social network” has become common, but those who use it to refer to social media as Facebook or Instagram often ignore its origin and its true meaning. The study of social networks precedes the advent of digital technologies. Since the 1930s, sociologists have been conducting surveys to describe the structures of relationships that unite individuals and groups: their “networks”. These include, for example, advice relationships between employees of a company, or friendship ties between students in a school. These networks can be represented as points (students) united by lines (links).
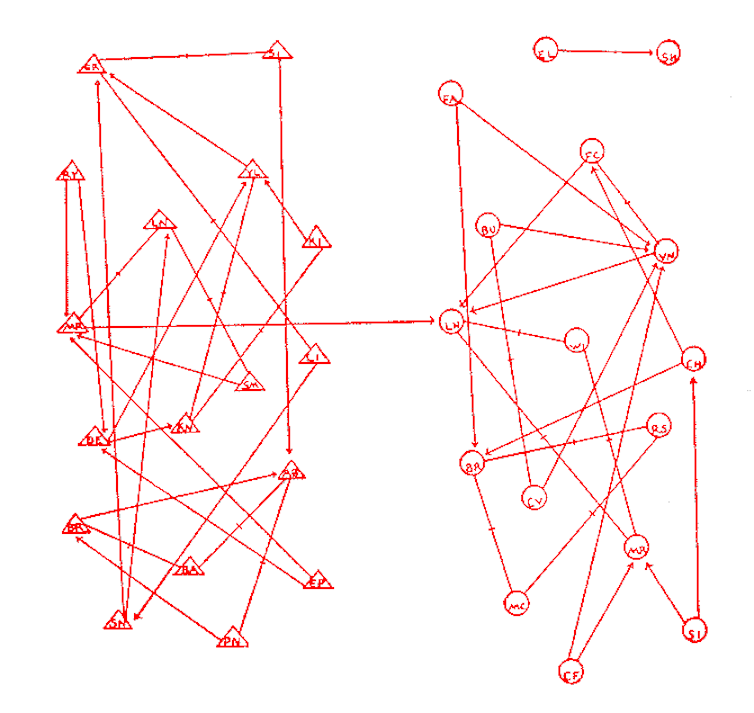
J.L. Moreno, Who shall survive? 1934.
Before any questioning on the social aspects of Facebook and Twitter, this research shed light on, for example, marital role segregation, importance of “weak ties” in job search, informal organization of firms, diffusion of innovations, formation of business elites, social support for the sick or elderly. Designers of digital platforms such as Facebook have picked up some of the analytical principles on which these works were based, developing them with the mathematical theory of graphs (though often with less attention to the social issues involved).
Early on, researchers in this field realized that the traditional principles of research ethics (focusing on informed consent of study participants and anonymization of data) were difficult to ensure. By definition, social networks research is never about a single individual, but about relationships between this individual and others – their friends, relatives, collaborators or professional advisors. If the latter are reported by the respondent but are not themselves included in the study, it is difficult to see how their consent could be obtained. What’s more, results can be difficult to anonymize, in that visuals are sometimes disclosive even in the absence of personal identifiers.
Ethics in the digital society: a minefield
Academics have long been thinking about these ethical difficulties, to which a special issue of the prestigious Social Networks journal was dedicated as far back as 2005. Today, researchers’ dilemmas are exacerbated by the increased availability of relational data collected and exploited by digital giants like Facebook or Google. New problems arise as the boundaries between “public” and “private” spheres become confused. To what extent do we need consent to access messages that digital service users send to their contacts, their “retweets”, or their “likes” on their friends’ walls?
These sources of information are often the property of commercial enterprises, and the algorithms they use likely bias observations. For example, can we interpret in the same way a contact created spontaneously by a user, and a contact created as a result of an automated recommendation system? In short, the data do not speak for themselves, and before thinking about their analysis, we must question the conditions of their use and the methods of their production. They largely depend on the software architectures imposed by platforms as well as their economic and technical choices. There is a real power asymmetry between platforms – often the property of large multinational companies – and researchers – especially those working in the public sector, and whose objectives are misaligned with investors’ priorities. Negotiations (if possible at all) are often difficult, resulting in restrictions to proprietary data access – particularly penalizing for public research.
Other problems arise as a researcher may even use paid crowdsourcing to produce data, using platforms like Amazon Mechanical Turk to ask large numbers of users to complete a questionnaire, or even to download their online contact lists. But these services raise numerous questions in terms of workers’ rights, working conditions and appropriation of the product of work. The resulting uncertainty hinders research that could otherwise have a positive impact on knowledge and on society at large.
Availability of online communication and publication tools, which many researchers are now seizing, increases the likelihood that research results may be diverted for political or business purposes. If the interest of military and police circles for the analysis of social networks is well known (Osama Bin Laden was allegedly located and neutralised following the application of social network analysis principles), these appropriations are more frequent today, and less easily controllable by researchers. A significant risk is the use of these principles to suppress civic and democratic movements.
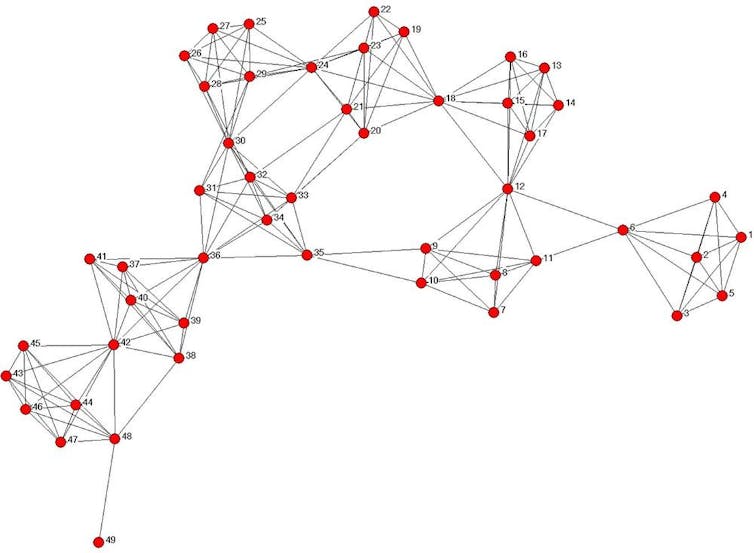
Kouznetsov A., Tsvetovat M., Social Network Analysis for Startups, 2011
The role of the researcher
Restrictions and prohibitions would likely aggravate the constraints that already weigh on researchers, without helping them overcome these obstacles. Rather, it is important to create conditions for trust and enable researchers to explore the full extent and importance of online and offline social networks – allowing them to capture salient economic and social phenomena while remaining respectful of people’s rights. Researchers should take an active role, participating in the co-construction of an adequate ethical framework, grounded in their experience and self-reflective attitude. A bottom-up process involving academics as well as citizens, civil society associations, and representatives of public and private research organizations could then feed these ideas and thoughts back to regulators (such as ethics committees).
Antonio A. Casilli, Associate professor Télécom ParisTech, research fellow Centre Edgar Morin (EHESS)., Télécom ParisTech – Institut Mines-Télécom, Université Paris-Saclay et Paola Tubaro, Chargée de recherche au LRI, Laboratoire de Recherche Informatique du CNRS. Enseignante à l’ENS, Centre national de la recherche scientifique (CNRS)
La version originale de cet article a été publiée sur The Conversation.





