INDL-9 will take place between 9 and 11 September 2026 and will be hosted by the International Labour Organization in beautiful Geneva, Switzerland.
INDL conferences provide a unique opportunity to share knowledge and new perspectives in research and practice related to digital labor.
The topic of this year, “AI Supply Chains,” has the ambition to build an interdisciplinary research agenda on AI and work. Submissions are particularly encouraged in the following thematic areas:
• Transparency and traceability in the AI models and their supply chains • Working conditions, occupational safety and health of workers in the human-in-the-loop • Best practices for ethical AI procurement and corporate social responsibility in data labelling • Role of social dialogue in governing AI-mediated work • Organisational, legal and financial perspectives on the rate of investment of ethical AI and challenges of regulatory compliance (eg., the EU AI Act) • New frameworks for a “human-centric” AI supply chain • Ecological impacts and environment sustainability of AI infrastructures
Proposals are also invited in topic areas that previously garnered substantial interest from conference presenters:
• Algorithmic management, labor control, and workers’ resistance • Platform cooperativism and alternative business models • Legal frameworks, regulatory initiatives, and institutional responses to platform labor • Gender and digital labor
There are two main ways in which a discipline like sociology engages with artificial intelligence (AI) and is affected by it. In a previous post, I discussed how the sociology of AI understands technology as embedded in socio-economic systems and takes it as an object for research. Here, focus is on sociology with AI, indicating that the discipline is integrating AI into its methodological toolbox.
AI technologies were designed for other-than-research purposes, but they may be repurposed. The editors of a special issue of Sociologica last year stress that, ten years ago, digital methods presented similar challenges: for example, using tweets to make claims about the social world required us to understand how people used Twitter in the first place. We also needed to understand which people used Twitter at all, and what spaces of action the architecture and Terms of Use of this platform allowed. Likewise, using AI technologies can serve sociologists insofar as efforts are made to understand the technological (and socio-economic) conditions that produced them. Because AI systems are typically blackboxed, this requires, to begin with, developing exploration techniques to navigate them. For example, the plot below is from a recent paper that asked five different LLMs to generate religious sermons and compared the results (readability scores) by religious traditions and race. It finds that Jewish and Muslim synthetic sermons were constructed with significantly more difficult reading levels than were those for evangelical Protestants, and that Asian religious leaders were assigned more difficult texts than other groups. It is a way to uncover how models treat religious and racial groups differently, although it remains difficult to detect precisely which factors affect this result.
Robust regression coefficients predicting readability scores by religion, race, and model. Source: Tom J.C., Ferguson T.W. & Martinez B.C. 2025. Religion and racial bias in Artificial Intelligence Large Language Models. Socius: Sociological Research for a Dynamic World, 11. https://doi.org/10.1177/23780231251377210
That said, how can AI help us methodologically? To answer this question, it is useful to look at qualitative and quantitative approaches separately. Qualitative research, traditionally viewed and practiced as an intensely human-centred method, may seem at first sight incompatible with it. However, use of computer-assisted qualitative data analysis (with tools such as Nvivo) is now common among qualitative researchers, though it faced some degree of scepticism at the beginning. Attempts to leverage AI move forward this agenda, and the most common application so far is automated transcription of interviews through speech recognition technologies. AI-powered tools make this otherwise tedious task more efficient and scalable. A recent special issue of the International Journal of Qualitative Methods maps a variety of other usages, less common and more experimental: for example, considering that even the best models for audio transcription are not as accurate as humans, LLMs appear as tools to facilitate and speed up transcription cleaning. There are also some attempts at using LLMs as instruments for coding and thematic analysis: for example, some authors have examined inter-coder reliability between ‘human only’ and ‘human-AI’ approaches. Others have used AI image generation like vignettes – as a tool for supporting interview participants in articulating their experiences. Overall, the use of AI remains experimental and marginal in the qualitative research community. Those who have undertaken these experiments find the results encouraging, but not perfect.
In quantitative research, some AI tools are already (relatively) widely used: in particular, natural language processing (NLP) to process textual data like corpora from the press or media. More recent applications leverage generative AI, especially large language models (LLM). Outside practices like literature review and code generation/debugging, which are common to multiple disciplines, three applications are specifically sociological and worth mentioning. First, in experimental research, there are some attempts to examine how the introduction of AI agents in interaction games shapes the behaviour of the humans they play with. As discussed by C. Bail in an insightful PNAS article, the extent to which generative AI is capable of impersonating humans is nevertheless subject to debate, and it will probably evolve over time. Second, L. Rossi and co-authors outline that in agent-based models (ABM), an idea is to use LLMs to create agents that are more capable of capturing a larger spectrum of human behaviours. While this approach may provide more realistic descriptions of agents, it re-ignites a long-standing debate in the field: indeed, many believe that increasing the complexity of agents is undesirable when emergent collective dynamics can emerge from more parsimonious models. It is also unclear how the performance of LLMs within ABMs should be evaluated. Shall we say that they are good if they reproduce known collective dynamics within ABMS? Or, should they be assessed based upon their capacity to predict real-world outcomes? Third, in survey research, the question has arisen whether LLMs can simulate human populations for opinion research. Some studies have tested this possibility, with mixed results. The most recent available evidence, in an article by J. Boelaert and co-authors, is that: 1) current LLMs fail to accurately predict human responses, 2) they do so in ways that are unpredictable, as they do not systematically favor specific social groups, and 3) their answers exhibit a substantially lower variance between subpopulations than what is found in real-world human data. In passing, this is evidence that so-called ‘bias’ does not necessarily operate as expected – LLM errors do not stem primarily from unbalanced training data.
These applications face specific ethical challenges. First, studies that require humans to interact with AI may expose them to offensive or inaccurate information, the so-called ‘AI hallucinations’. Second, there are new concerns about privacy and confidentiality. Most GenAI models are the private property of companies: if we use them to code in-depth interviews about a sensitive topic, the full content of these interviews may be shared with these companies, often not bound by the same standards and regulations in terms of personal data protection. Third, the environmental impact of these models is high, in terms of energy to run the system, water to cool servers in data centres, metal extraction to build devices, and production of e-waste. The literature on AI-as-object also warns that there is a cost in terms of the unprotected human work of annotators.
Another limitation is that is that research with Generative AI is difficult to replicate. These models are probabilistic in nature: even identical prompts may produce different outputs, in ways that are not well understood as of today. Also, models are constantly being fine-tuned by their producers in ways that we as users do not control. Finally, different LLMs have been found to produce substantially different results in some cases. Many of these issues are due to the proprietary nature of most models – so much so that some authors like C. Bail believe that open-source models devoted to, and controlled by, researchers can help address some of these challenges.
Overall, AI has slowly entered the toolbox of the sociologist, and except for some applications that are now commonplace (from automated transcriptions to NLP), its use has not completely revolutionised practices. This pattern is not exclusive to sociology. My own study of the diffusion of AI in science until 2021, as part of the ScientIA project led by F. Gargiulo, showed limited penetration in almost all disciplines, although the last two years have seen a major acceleration. The opportunities that AI offers are promising, although a lot are more hypothetical than real at the moment. We still see calls that invite sociologists and social scientists to embrace AI, but the number of realizations is still small. Almost all applications devote time to consider the epistemological, methodological, and substantive implications. A question that often emerges concerns the nature of bias. The AI-as-object perspective challenges the language of bias, and we see the same here, though from a different perspective. There’s still no shared definition of bias (or any substitute for this term). More generally, patterns are similar in qualitative and quantitative studies. The guest-editors of last year’s special issue of Sociologicasuggest that, like digital methods 10-15 years ago, generative AI is supporting a move beyond the traditional qualitative/quantitative divide.
Concluding, both Sociology-of-AI and Sociology-with-AI exist and are important, but they are not well integrated. This is one of the bottlenecks for the development of the methodological toolbox of sociology, but also for the development of an AI that is useful and positive for people and societies. In part, this may be due to lack of adequate (technical) training for part of the profession, or to the absence of guidelines (for ethics and/or scientific integrity). But perhaps, the real obstacles are less immediately visible. One of them is the difficulty to judge the uptake of AI in our discipline: are we just feeding the hype if we use it? Or are we missing a major opportunity to make sociology more relevant/stronger if we don’t? The other concerns the questions and issues that go beyond the specificities of sociology. How to continue interacting with other disciplines, while upholding the distinctive contribution of sociology?
There are two main ways in which a discipline like sociology engages with artificial intelligence (AI) and is affected by it. The sociology of AI understands technology as embedded in socio-economic systems and takes it as an object for research. Sociology with AI indicates that the discipline is also integrating AI into its methodological toolbox. Based on a talk that I gave at this year’s annual meeting of the European Academy of Sociology, I’ll give in what follows a brief overview of both. As a disclaimer, I have no pretention to be exhaustive. To narrow down the topic, I have chosen to focus on sociology specifically (rather than neighboring fields), and to rely only on already published, peer-reviewed research.
Let’s start with the sociology of AI, which I’ll illustrate with the help of the above artwork. Its aim is to demonstrate that even if there is a sense of magic in looking at the outputs of an AI system, the data on which it is based has a human origin. This work explores this idea through the symbolism of the mirror and reflection: beyond the magic, these outputs are a reflection of society. Sociological perspectives matter because they can help bring these social and human origins to the fore. In 2021, Kelly Joyce and her coauthors called for more engagement of sociologists in outlining a research agenda around these topics. Compared to other disciplines, we have a thicker understanding of the intersectional inequalities and social structures that interact with AI.
Why does the quasi-absence of sociology matter? I’ll answer this question through a 2022 paper, written by two sociologists but published in a computer science conference. The starting point is that early studies framed AI-related societal problems in terms of bias. For example, the above-mentioned report on predictive policing was entitled “machine bias”. This language points to technical corrections as remedy, but it cannot account for the social processes underway that comprise, among other things, increasing surveillance and privacy intrusion to collect more and more data (see image below). De-biasing may thus be insufficient to prevent injustice or inequality. A sociologically informed approach reveals that key questions are about power: who owns data and systems, whose worldviews are being imposed, whose biases we are trying to mitigate.
In recent years, more substantial contributions have been made within sociology. For example, there was a special issue of Socius last year on “Sociology of Artificial Intelligence”, and another one is forthcoming in Social Science Computer Review, entitled “What is Sociological About AI?”. I’ll mention a non-exhaustive selection of topics and findings. First, sociologists have recognized the hype – or how financial, political, and other interests have boosted the circulation of (often) exaggerated claims. This means shifting the gaze from AI as an intellectual endeavor, to see AI as a market – where bubbles can, well, form. This also means recognizing the political dimensions of AI development, with many states using public funding as a crucial engine for innovation.
Second, AI practitioners engage in a form of social construction of morality to legitimate their approaches to AI. For example, some distance themselves from Big Tech capitalism, some insist on the benefits of some AI applications, most prominently in healthcare. These efforts ultimately shape which technologies gain visibility and attract capital investments. This is also a way through which they produce and sustain the AI bubble itself – a culturally embedded market phenomenon. Third, sociological analysis can move beyond the technological determinism of early AI critics to emphasize the social and institutional contexts within which such algorithmic decision-making systems are deployed. This brings to light forms of negotiation, adaptation, and resistance, which have more subtle effects on inequalities.
In sum, sociologists increasingly contribute to these conversations, although these topics are not prominent in the discipline’s flagship conferences and journals, and important knowledge gaps remain. The guest-editors of the forthcoming Social Science Computer Review special issue on “What is sociological about AI?” claim that “A sociological lens can render AI’s hidden processes legible, just as sociologists have done with complex and taken for granted social forces since the discipline’s inception”. They nevertheless note that “we neither have a robust concept of AI as a social phenomenon nor a holistic sociological discourse around it, despite vibrant and dynamic work in the area.” In passing, most extant studies rely on traditional methods, primarily surveys and fieldwork. This is not an issue in itself, but it highlights a disconnection with the sub-topic I’ll highlight in my next post – Sociology using AI as instrument.
When we created ENDL (the European Network on Digital Labour), back in 2017, we booked a room with 17 places. A few days ago, the last conference of the network (which in the meantime has become INDL, replacing ‘European’ with ‘International’) hosted about 200 participants. Internationalisation has not only meant numerical growth, but also inclusion of a diverse range of voices: every year, we see more participants from countries that are often under-represented on the scientific scene, from India and South Africa to Argentina and Brazil. Participants have also diversified in another sense, too: if the majority have always been academics, it is a pleasure to see more and more workers, as well as labour organisers. This year, we could for example benefit from the presence of associations of data workers from Kenya, freelancers from France, and content moderators from Spain.
Participants to the INDL-8 conference, Saint-Cristina cloister, Bologna, IT, 10 September 2025.
A conference like this one is meant to give hope – hope of mutual understanding across countries and cultures, hope of dialogue across disciplines and fields, hope of connections between academic research and action. We worked together to ensure a welcoming environment for all, for instance by encouraging constructive comments, rather than sheer criticism, after each paper presentation. We also strived to keep costs down in order to make the conference free of charge, and with the DiPLab research programme, we could give a few small scholarships to promising presenters who might not have been able to travel otherwise.
Two speakers (M Francesco Sinopoli, Fondazione Di Vittorio, and Ms Kauna Malgwi, Uniglobal) at the plenary panel ‘Plenary panel: New Unionism, towards global alliances’, part of the INDL-8 Conference, DAMA Tecnopolo, Bologna, IT, 11 September 2025
Surely, problems remain. A couple potential participants had visa issues, while others had to cancel due to lack of funding. These problems weigh especially hard on people from emerging and lower-income countries outside Europe and North America. The future is also uncertain, as funding sources become increasingly dryer, and visa restrictions tighter. For this reason, the main INDL-9 conference next year (Geneva, ILO, 9-11 September 2026) will be accompanied by the growth of local chapters. The Middle-East and Africa area is preparing its second conference, this time online only, on 25-26 November. In the US, a one-day event will take place at Yale University on 29 April 2026. Colleagues in Chile and Argentina are launching a series of online events.
Closing keynote (Prof. Sandro Mezzadra, chair: Prof. Marco Marrone), Saint-Cristina Aula Magna, Bologna, IT, 12 September 2025
More information on the INDL-8 conference (including the full programme) is available here.
I am attending a faboulous Sunbelt conference, taking place this year in Paris. I am deeply grateful to Emmanuel Lazega who made gigantic efforts to bring this important conference to France, after a failed attempt in 2020 when the Covid-19 pandemic brought everything online.
Yesterday, a very inspiring keynote by Beate Völker reminded us of the importance of weak ties and even absent ties – not only to smoothen the functioning of job markets but also, more surprisingly, to achieve social cohesion. The keynote took place in the historical Grand Amphithéâtre de la Sorbonne.
I am pleased to have contributed to a set of initiatives in honour of great network sociologist Harrison White, one year after his death. With Elise Penalva-Icher and Fabien Eloire, we presented a paper on digital platforms in White-like producer markets shaped by networks (more on it soon!). The paper was part of a dedicated session on the legacy of Harrison White. There was also a plenary in memoriam, where his former students and friends shared thoughts and stories. (Another plenary honoured Barry Wellman).
I was also honoured to be invited, today, to join a plenary panel on social networks and the study of social inequalities, organized by Gianluca Manzo. While most research on inequalities is attribute-based, social network approaches provide a powerful alternative (or perhaps, complement), highlighting how interpersonal, relational mechanisms generate patterns that over time, lock categorical differences into durable gaps in wealth, status, or other outcomes. We discussed complementarities and differences between these two approaches, the advantages of a network-oriented perspective, but also the methodological challenges that come with it.
On Sunday, I’ll present a paper that also deals with inequalities, in the specific case of online platform workers. We define an index of ‘vulnerability’ to unveil inequalities within this worker population in two countries, France and Spain. The paper develops and deeps results of a previous work, whose first outputs served to inform policy decisions in France.
Another paper to which I have contributed, and which will be presented at this Sunbelt, is more methodological and is the result of a collective effort. We analyze over 20 years of publications in the journal REDES and highlight how researchers have reported relational data from both personal and complete networks. We identify key challenges in the consistency and transparency of reporting and propose 7 practical recommendations to improve clarity, comparability, and replicability in social network research. This paper is already published in REDES.
The conference reaches Italy this year. It will take place in the most ancient University in the western world, Bologna, on 10-12 September 2025.
The overarching topic of this year’s conference is ‘Contesting Digital Labor: Resistance, counteruses, and new directions for research’. The goal is to explore how platform workers navigate, challenge, and reshape algorithmic management systems while forging innovative forms of solidarity and collective action. We also aim to explore the perspectives that technological developments open for workers in order to escape everyday surveillance, to resist top-down control and to organise to defend their rights.
In addition to presentations that directly address these questions, we welcome proposals that analyse a broader range of issues related to digital labour.
A few years ago, when hopes to leverage technology to build a more humane “sharing” economy had not yet completely vanished, it was often believed that the most interesting policy experiments were to be found at the local level of cities, not states. One of those was the urban-planning concept of a 15-minute city, aiming to make any essential amenities such as schools and shops accessible within a 15-min walk or bike ride. Launched in Paris before receiving enthusiastic support worldwide, it was part of the current mayor’s latest re-election campaign.
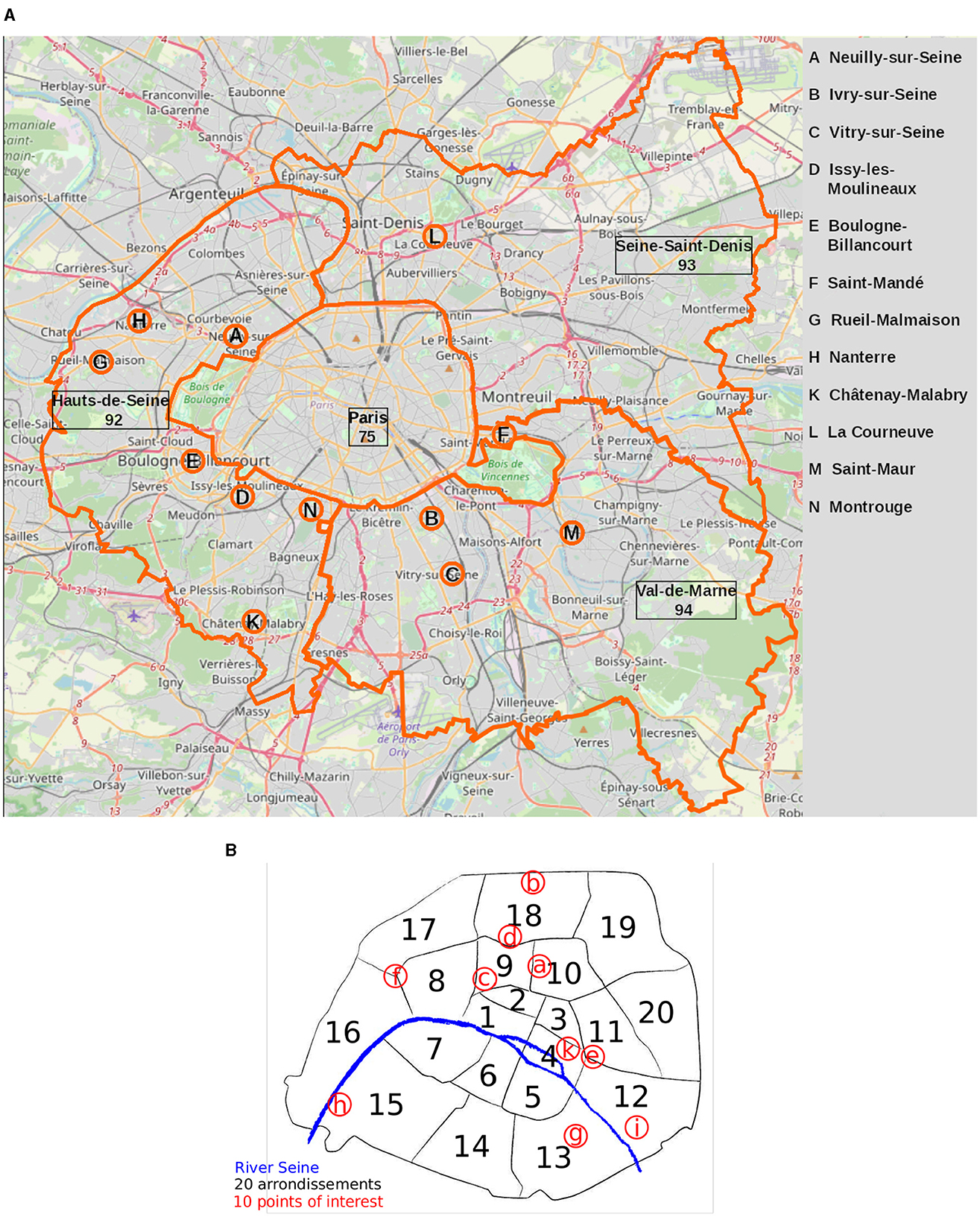
Fast forward to today, and how actually far is Paris from the 15-min goal? Sarah J. Berkemer and I have endeavoured to answer this question in a just-published article (available in open access!) with three brilliant ENSAE students (Marie-Olive Thaury, Simon Genet and Léopold Maurice). We harness open map data from the large participatory project Open Street Map and geo-localized socio-economic data from official statistics (Insee) to fill this gap.
While the city of Paris is rather homogeneous, we show that it is nonetheless characterized by remarkable inequalities between a highly accessible city centre (though with some internal differences in terms of types of amenities) and a less equipped periphery, where lower-income neighborhoods are more often found. Heterogeneity increases if we consider Paris together with its immediate surroundings, the “Petite Couronne,” where large numbers of daily commuters and other users of city facilities live.
We find that this ambitious urban planning objective cannot be achieved without addressing existing socio-economic inequalities, and that especially in a big city like Paris, it cannot be confined within the narrow boundaries of the municipality itself, without also including the city’s immediate surroundings.
One reason why I am particularly proud of this work is that it demonstrates how far research-informed teaching can go. Most higher education is about familiarizing students with generally accepted and confirmed knowledge, without going beyond the state of the art. This is certainly important and in all cases a “safe” bet, but does not give students a sense of what it means to push the boundaries further. This project was an opportunity to do so. It gave students the role of researchers – our peers – letting them play the role in full and showing them all the back-office work that lies behind publications (from drafting to responding to reviews and copy-editing), and that is (too) often occluded from students’ view. There’s probably more to experiment around this model.
Most of my current research aims to unpack artificial intelligence (AI) from the viewpoint of its commercial production, looking in particular at the human resources needed to prepare the data it needs – whence my studies on the data work and annotation market. However, for once, I am focusing on AI as a set of scientific theories and tools, regardless of their market positioning; indeed, I have joined a team of science-of-science specialists to study the disciplinary origins and subsequent spread of AI over time.
In a newly published, open-acces article, we unveil the disciplinary composition of AI, and the links between its various sub-fields. We question a common distinction between ‘native’ and ‘applicative’ disciplines, whereby only the former (typically confined to statistics, mathematics, and computer science) produce foundational algorithms and theorems for AI. In fact, we find that the origins of the field are rather multi-disciplinary and benefit, among others, from insights from cognitive science, psychology, and philosophy. These intersecting contributions were most evident in the historical practices commonly known as ‘symbolic systems’. Later, different scientific fields have become, in turn, the central originating domains and applicators of AI knowledge, for example operations research, which was for a long time one of the core actors of AI applications related to expert systems.
While the notion of statistics, mathematics and computer science as native disciplines has become more relevant in recent times, the spread of AI throughout the scientific ecosystem is uneven. In particular, only a small number of AI tools, such as dimensionality reduction techniques, are widely adopted (for example, variants of these techniques have been in use in sociology for decades). But if transfer of AI is largely ascribable to multi-disciplinary interactions, very few of them exist. We observe very limited collaborations between researchers in disciplines that create AI and researchers in disciplines that only (or mainly) apply AI. The small core of multi-disciplinary champions who interact with both sides, and the presence of a few multi-disciplinary journals, sustains the whole system.
Inter- and multi-disciplinary interactions are essential for AI to thrive and to adequately support scientific research in all fields, but disciplinary boundaries are notoriously hard to break. Strategies to better reward inter-disciplinary training, publications, and careers, are thus essential. Of course the potential for AI to significantly advance knowledge is still (largely) to be proven, and there have been disappointing experiences with, for example, the comparatively limited effectiveness of these tools in research on Covid-19. In all cases, the status quo is not ideal, and important steps forward are now needed.
We establish these results by analyzing a large corpus of scientific papers published between 1970 and 2017, extracted from Microsoft Academic Graph through the AI keywords used by the authors, and explored with different relational structures among the scientometric data (keyword co-occurrence network, authors’ collaboration network).
Full citation: Floriana Gargiulo, Sylvain Fontaine, Michel Dubois, Paola Tubaro. A meso-scale cartography of the AI ecosystem. Quantitative Science Studies, 2023; doi: https://doi.org/10.1162/qss_a_00267
Today, I end my 3-month-and-half visit to Churchill College, University of Cambridge where I am a By-Fellow. It has been an amazingly enriching experience and I gratefully acknowledge financial support from the French Embassy in the United Kingdom. Colleges are special places where traditional elitism mixes with more modern tendencies toward openness and diversity. I think the great value of colleges rests in their deeply interdisciplinary culture – way beyond what one may find in university departments and research centres. In my short stay, I have had lots of mind-opening conversations with scholars from all domains (often while enjoying a nice meal together), always with the feeling that people listen and learn from each other rather than that sense of constant competition that I have often perceived when crossing disciplinary boundaries.
My by-fellowship would not have been possible without the support of Gina Neff and her colleagues at Minderoo Centre for Technology and Democracy who hosted me. They are doing extremely valuable work to rethink the social and environmental impact of technologies and to promote innovative and more sustainable ways forward. I was also honoured to collaborate with the team of Cambridge Digital Humanities, especially Anne Alexander who directs the Learning programme and invited me to give two sessions on social network analysis at the Social data School last June. Finally, I thank the director and the members of the CRASSH research centre (where Minderoo is based) who kindly welcomed me at their offices and gave me the opportunity to attend some of their recent events.
We examine the implications of the use of digital micro-working platforms for scientific research. Although these platforms offer ways to make a living or to earn extra income, micro-workers lack fundamental labour rights and ‘decent’ working conditions, especially in the Global South. We argue that scientific research currently fails to treat micro-workers in the same way as in-person human participants, producing de facto a double morality: one applied to people with rights acknowledged by states and international bodies (e.g. Helsinki Declaration), the other to ‘guest workers of digital autocracies’ who have almost no rights at all.