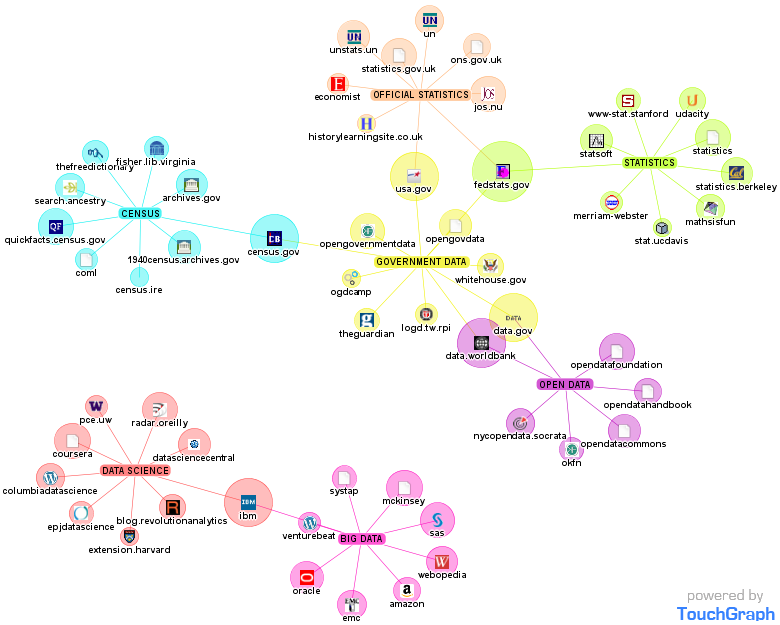
National Statistical Institutes (NSIs) have long been the recognised repositories of all socio-economic information, mandated by governments to collect and analyse data on their behalf. The development of big data is shaking this world. New actors are coming in and commercially-oriented, privately-produced information challenges the monopoly of NSIs. At the same time, NSIs themselves can tap into digital technologies and produce “big” data. More generally, these new sources offer a range of opportunities, challenges and risks to the work of NSIs.
 The Statistical Journal of the IAOS, the flagship journal of the International Association for Official Statistics, has published a special section on big data – of particular interest to the extent that it is free of charge!
The Statistical Journal of the IAOS, the flagship journal of the International Association for Official Statistics, has published a special section on big data – of particular interest to the extent that it is free of charge!
Fride Eeg-Henriksen and Peter Hackl introduce this special section by defining big data and emphasising its interest for official statistics. But it is crucial, albeit admittedly not easy, to separate the hype around big data from its actual importance.
The other papers are concrete examples of how big data may be integrated into official statistics:
Continue reading “New publications on big data and official statistics”