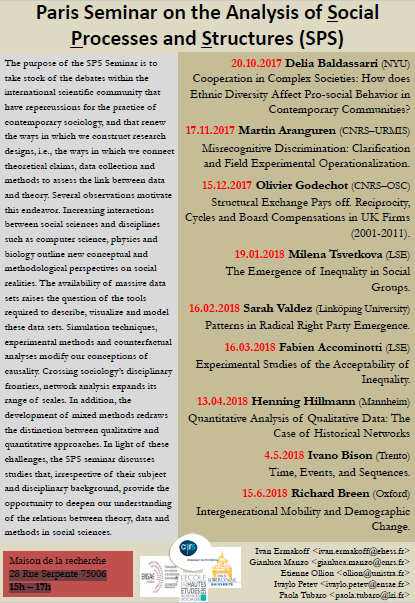
Our inter-disciplinary, inter-institutional SPS seminar (Paris Seminar on the Analysis of Social Processes and Structures) has just started its second edition! Its purpose is to take stock of the debates within the international scientific community that have repercussions on the practice of contemporary sociology, and that renew the ways in which we construct research designs, i.e., the ways in which we connect theoretical claims, data collection and methods to assess the link between data and theory. Several observations motivate this endeavor. Increasing interactions between social sciences and disciplines such as computer science, physics and biology outline new conceptual and methodological perspectives on social realities. The availability of massive data sets raises the question of the tools required to describe, visualize and model these data sets. Simulation techniques, experimental methods and counterfactual analyses modify our conceptions of causality. Crossing sociology’s disciplinary frontiers, network analysis expands its range of scales. In addition, the development of mixed methods redraws the distinction between qualitative and quantitative approaches. In light of these challenges, the SPS seminar discusses studies that, irrespective of their subject and disciplinary background, provide the opportunity to deepen our understanding of the relations between theory, data and methods in social sciences.