
Data are not a new ingredient of socio-economic research. Surveys have served the social sciences for long; some of them like the European Social Survey, are (relatively) large-scale initiatives, with multiple waves of observation in several countries; others are much smaller. Some of the data collected were quantitative, other qualitative, or mixed-methods. Data from official and governmental statistics (censuses, surveys, registers) have also been used a lot in social research, owing to their large coverage and good quality. These data are ever more in demand today.
Now, big data are shaking this world. The digital traces of our activities can be retrieved, saved, coded and processed much faster, much more easily and in much larger amounts than surveys and questionnaires. Big data are primarily a business phenomenon, and the hype is about the potential gains they offer to companies (and allegedly to society as a whole). But, as researcher Emma Uprichard says very rightly in a recent post, big data are essentially social data. They are about people, what they do, how they interact together, how they form part of groups and social circles. A social scientist, she says, must necessarily feel concerned.
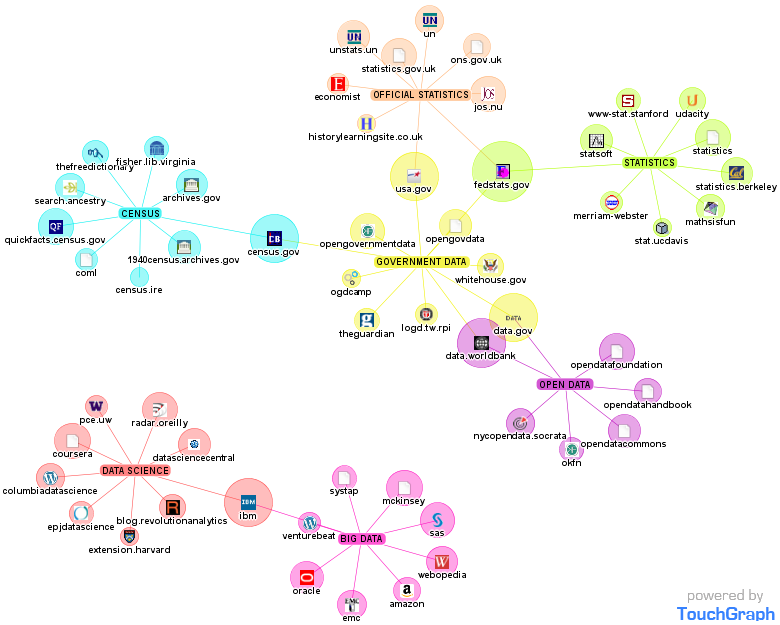
It is good, for example, that the British Sociological Association is organizing a one-day event on The Challenge of Big Data. It is a good point that members must engage with it. This challenge goes beyond the traditional qualitative/quantitative divide and the underrepresentation of the latter in British sociology. Big data, and the techniques to handle them, are not statistics, and professional statisticians have trouble with it too. (The figure below is just anecdotal, but clearly suggests how a simple search on the Internet identifies Statistics and Big Data as unconnected sets of actors and ties). The challenge has more to do with the a-theoretical stance that big data seem to involve.
The idea that we can get rid of social theories and old-style fieldwork and surveys just because we now have big data, is grounded in the role that theory used to have in the past: to compensate for lack of data. Because we no longer have this problem, we no longer need theory, so goes the argument. But a less superficial look at what big data is suggests instead that the need for theory does not go away: Rather, the functions of theory change, as it now serves to interpret these data. We know that big data are unstructured and noisy, and difficult to interpret. We need good information about data quality, we need assumptions and hypotheses to test, we need ethical awareness throughout the process, from data collection to data analysis and release of results and ensuing recommendations. We must be able to control the analysis of any big data within a theoretical framework that gives meaning to it.
So, big data are an opportunity, but also a challenge for the social sciences: will we be able to develop our theories to cope with these data? Will we be able to renounce it in favor of other (“small data”) approaches when they are more helpful for theoretical reflection? These are new, and important, questions for the social sciences (regardless of older qualitative/quantitative divisions) to answer in the near future.

In 2007 the British sociologists Mike Savage and Roger Burrows opened up the issue of “big (transactional) data” and its meaning for empirical sociology. Shameless plug: with Stephanie Steinmetz and Paul Wouters we have written an essay investigating how new data sources were challenging sociology indeed, but also economics in a different way. The pdf can be downloaded here: http://www.clementlevallois.net/download/datafloods_2013.pdf
Thanks very much for pointing to this a very interesting article. I very much like your (and your co-authors’) up-front approach to the question of whether “new” data imply the end of social theory – and I certainly sympathize with the “NO” answer resulting from your analysis of the cases of economics and sociology!
This article offers a lot of food for thought and I have come up with a couple of questions – not criticisms, just open questions, really – about, precisely, the case studies.
– In sociology: while it makes perfect sense to contrast “old” quantitative methodologies such as surveys and today’s transactional/Internet/commercial data, I still don’t see clearly what is the impact on *qualitative* sociology. To what extent, and how, are big data affecting scholars who always refrained from even the slightest attempt at quantification?
– In economics: what is the actual diffusion of neuroeconomics? Despite its bold claims, it still seems to concern only a handful of researchers, and in terms of PhD dissertations in this area, we are still talking single digits a year…
– Again in economics, I am a bit surprised not to see much impact from the same data that are now challenging sociology: Internet data and the like. True, economists never liked surveys, but are still sticking very much to their traditional sources (official statistics, administrative data) and some new, but still “small” data (RCTs), without showing much enthusiasm for big data. Is it because they are more aware than others of the limitations of these data (lack of structure, thin or nonexistent documentation) – or are they just exaggerating these limitations?
Anyway, thanks again for offering material for reflection!