
The rise of digital data, particularly data from the internet, is to be understood in social relational perspective. Online interactions – from email exchanges to use of VOIP services and participation in social media such as Facebook, Twitter and LinkedIn – make people’s social connections explicit and visible. The “social network”, once a metaphor used only in a small sub-field within sociology, is now familiar to everybody as the archetype of computer-mediated social interaction. Digital devices systematically record network structures, so that social ties become an essential part of every individual profile, and users are more and more aware of them.
One consequence of this is the booming popularity of network analysis concepts, which support the algorithms that handle digital data: for example, centrality measures are at the heart of search engine functionalities, and transitivity measures found “friend-of-a-friend” algorithms in social media. In passing, social network analysis itself which had been originally developed for small-sized, non-digital datasets (like surveys about friendship in schools) has undergone a major upgrade to account for social data from the web.
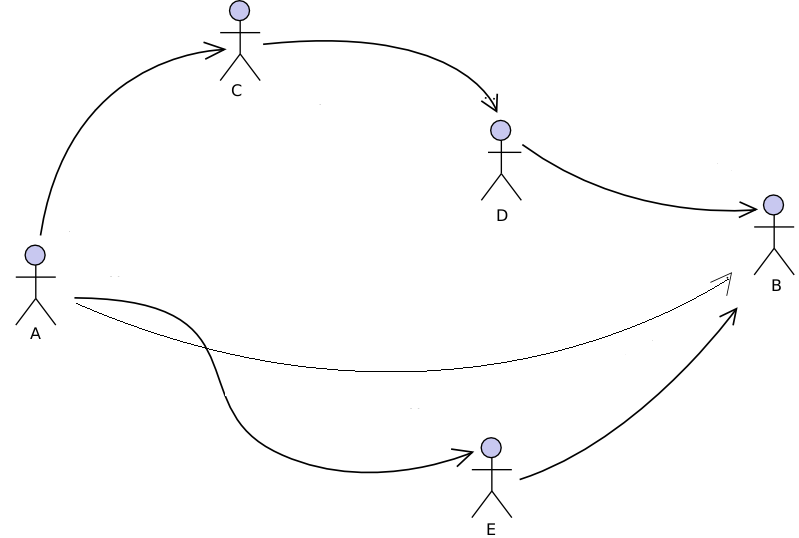 More importantly, the relational nature of digital data and the underlying possibilities to use social network analysis, open up new avenues for data collection. If user B publishes a post on, say, their Facebook wall, comments and “likes” received from their friends A, D and E will be connected to the profile of B, accessible and visible from it; in other words, it is possible to retrieve information on A, D or E through the profile of just B. In general social networks, a friend of my friend is my friend; in digital networks, the data of my friends are my data.
More importantly, the relational nature of digital data and the underlying possibilities to use social network analysis, open up new avenues for data collection. If user B publishes a post on, say, their Facebook wall, comments and “likes” received from their friends A, D and E will be connected to the profile of B, accessible and visible from it; in other words, it is possible to retrieve information on A, D or E through the profile of just B. In general social networks, a friend of my friend is my friend; in digital networks, the data of my friends are my data.
This is good news for anyone willing to gather data for analysis – the relational structure of the digital world works like a “multiplier” that enhances the potential of any such effort. However, major confidentiality and privacy problems ensue. In traditional data collection exercises such as surveys, data subjects would have to give their informed consent; in the digital world, data collection is so straightforward that many analysts forget about consent. And even those who do bother seeking B’s consent, may find it practically very difficult to reach out to A, D and E too.
In addition, and perhaps more subtly, networked information may open the way to new, and untransparent, forms of discrimination. Because people are often found to cluster in groups that share important similarities (a phenomenon that the specialized literature often refers to as “homophily”), it is tempting to infer the characteristics of (say) A, based on the characteristics of E, B and C with whom A has ties. Algorithms using digital data can do that today, but A and their friends are unlikely to precisely know how. It may thus happen that a potential employer discriminates A because of their relationship with C – in a way that A is barely aware of.
Transparency and education become crucial. Transparency of algorithms, that online platforms and services should make more understandable to their users (I’m not arguing they should reveal details that undoubtedly constitute critical competitive assets, but just that they just make sure users understand the underlying logic, and the way it affects them). And education of users, who should be made more aware of the implications and consequences of navigating in a world of data flows.
To know more:
S.P. Gangadharan, ed. (2014). Data and Discrimination: Collected Essays. OTI Policy Paper.
F. Pasquale (2015). The Black Box Society: The Secret Algorithms That Control Money and Information. Harvard University Press.
