Another article has just been published! Another one that is based on a DiPLab-based group collaboration (with A.A. Casilli, M. Fernández Massi, J. Longo, J. Torres Cierpe and M. Viana Braz) and that uses data from multiple countries. It is entitled ‘The digital labour of artificial intelligence in Latin America: a comparison of Argentina, Brazil, and Venezuela’ and is part of a special issue of Globalizations on ‘The Political Economy of AI in Latin America’. This article lifts the veil on the precarious and low-paid data workers who, from Latin America, engage in AI preparation, verification, and impersonation, often for foreign technology producers. Focusing on three countries (Argentina, Brazil, and Venezuela), we use original mixed-method data to compare and contrast these cases in order to reveal common patterns and expose the specificities that distinguish the region.
The analysis unveils the central place of Latin America in the provision of data work. To bring costs down, AI production thrives on countries’ economic hardship and inequalities. In Venezuela and to a lesser extent Argentina, acute economic crisis fuels competition and favours the emergence of ‘elite’ (young and STEM-educated) data workers, while in more stable but very unequal Brazil, this activity is left to relatively underprivileged segments of the workforce. AI data work also redefines these inequalities insofar as, in all three countries, it blends with the historically prevalent informal economy, with workers frequently shifting between the two. There are spillovers into other sectors, with variations depending on country and context, which tie informality to inequality.
Our study has policy implications at global and local levels. Globally, it calls for more attention to the conditions of AI production, especially workers’ rights and pay. Locally, it advocates solutions for the recognition of skills and experience of data workers, in ways that may support their further professional development and trajectories, possibly also facilitating some initial forms of worker organization.
The version of record is here, while an open-access preprint is available here.
I am thrilled to announce that an important article has just seen the light. Entitled ‘Where does AI come from? A global case study across Europe, Africa, and Latin America’, it is part of a special issue of New Political Economy on ‘Power relations in the digital economy‘. It is the result of joint work that I have done with members of the Diplab team (A.A. Casilli, M. Cornet, C. Le Ludec and J. Torres Cierpe) on the organisational and geographical forces underpinning the supply chains of artificial intelligence (AI). Where and how do AI producers recruit workers to perform data annotation and other essential, albeit lower-level supporting tasks to feed machine-learning algorithms? The literature reports a variety of organisational forms, but the reasons of these differences and the ways data work dovetails with local economies have remained for long under-researched. This article does precisely this, clarifying the structure and organisation of these supply chains, and highlighting their impacts on labour conditions and remunerations.
Framing AI as an instance of the outsourcing and offshoring trends already observed in other globalised industries, we conduct a global case study of the digitally enabled organisation of data work in France, Madagascar, and Venezuela. We show that the AI supply chains procure data work via a mix of arm’s length contracts through marketplace-like platforms, and of embedded firm-like structures that offer greater stability but less flexibility, with multiple intermediate arrangements that give different roles to platforms. Each solution suits specific types and purposes of data work in AI preparation, verification, and impersonation. While all forms reproduce well-known patterns of exclusion that harm externalised workers especially in the Global South, disadvantage manifests unevenly depending on the structure of the supply chains, with repercussions on remunerations, job security, and working conditions.
Marketplace- and firm-like platforms in the supply chains for data work in Europe, Africa, and Latin America. Dark grey countries: main case studies, light grey countries: comparison cases. Organisational modes range from almost totally marketplace oriented (darker rectangle, Venezuela) to almost entirely firm oriented (lighter rectangle, Madagascar). AI preparation (darker circle) is ubiquitous, but AI verification (darker triangle) and AI impersonation (darker star) tend to happen in ‘deep labour’ and firm-like organisations where embeddedness is higher.
We conclude that responses based only on worker reclassification, as attempted in some countries especially in the Global North, are insufficient. Rather, we advocate a policy mix at both national and supra-national levels, also including appropriate regulation of technology and innovation, and promotion of suitable strategies for economic development.
The Version of record is here, while here is an open access preprint.
My great regret is that I always have very little time to write posts, and the emptiness of this blog does not reflect the numerous, great and stimulating scientific events and opportunities that I have enjoyed throughout 2024. As a last-minute remedy (with a promise to do better next year…hopefully), I try to summarize the landmarks here, month by month.
In January, I launched the Voices from Online Labour (VOLI) project, which I coordinate with a grant of about €570,000 from the French National Agency for Research. This four-year initiative brings together expertise from sociology, linguistics, and AI technology across multiple institutions, including four French research centres, a speech technology company, and three international partners.
In February with the Diplab team, I spent two exciting days at the European Parliament in Brussels, engaging in profound discussions with and about platform workers as part of the 4th edition of the Transnational Forum on Alternatives to Uberization. I chaired a panel with data workers and content moderators from Europe and beyond, aiming to raise awareness about the difficult working conditions of those who fuel artificial intelligence and ensure safe participation to social media.
In March, three publications saw the light. One is a solo-authored chapter, in French, on ‘Algorithmes, inégalités, et les humains dans la boucle‘ (Algorithms, inequalities, and the humans in the loop) in a collective book entitled ‘Ce qui échappe à l’intelligence artificielle‘ (What AI cannot do). The other two are journal articles that may seem a little less close to my ‘usual’ topics, but they are important because they constitute experiments in research-informed teaching. One is a study of the 15-minute city concept applied to Paris, realized in collaboration with a colleague, S. Berkemer of Ecole Polytechnique, and a team of brilliant ENSAE students. The other is an analysis of the penetration of AI into a specific field of research, neuroscience, showing that for all its alleged potential, it created a confined subfield but did not entirely disrupt the discipline. The study, part of a larger project on AI in science, was part of the PhD research of S. Fontaine (who has now got his degree!), also co-authored with his co-supervisors F. Gargiulo and M. Dubois.
In April, I co-published the final report from the study realized for the European Parliament, ‘Who Trains the Data for European Artificial Intelligence?‘. Despite massive offshoring of data tasks to lower-income countries in the Global South, we find that there are still data workers in Europe. They often live in countries where standard labour markets are weaker, like Portugal, Italy and Spain; in more dynamic countries like Germany and France, they are often immigrants. They do data work because they lack sufficiently good alternative opportunities, although most of them are young and highly educated.
I then attended two very relevant events. On 30 April-1 May, I was at a Workshop on Driving Adoption of Worker-Centric Data Enrichment Guidelines and Principles, organised by Partnership on AI (PAI) and Fairwork in New York city to bring together representatives of AI companies, data vendors and platforms, and researchers. The goal was to discuss options to improve working conditions from the side of the employers and intermediaries. On 28 May, I was in Cairo, Egypt, to attend the very first conference of the Middle East and Africa chapter of INDL (International Network on Digital Labour), the research network I co-founded. It was a fantastic opportunity to start opening the network to countries that were less present before, and whose voices we would like to hear more.
August is a quieter month (but I greatly enjoyed a session at the Paralympics in Paris!), so I’ll jump to September. Lots of activities: a trip to Cambridge, UK, and a workshop on disinformation at the Minderoo Centre for Technology and Democracy; a workshop on Invisible Labour at Copenhagen Business School in Denmark; and a one-day conference on gender in the platform economy in Paris. Another publication came out: a journal article, in Spanish, on Argentinean platform data workers.
At the end of October, and until mid-November, I travelled to Chile for the seventh conference of the International Network on Digital Labour (INDL-7), which I co-organised. It was an immensely rewarding experience. I took the opportunity to strengthen my linkages and collaborations with colleagues there. It was a very intense, and super-exciting, time: after INDL-7 (28-30 October), I spent a week in Buenos Aires, Argentina, where I co-presented work in progress at the XV Jornadas de Estudios Sociales de la Economía, UNSAM. I then returned to Chile where I gave a keynote at the XI COES International Conference in Viña del Mar, Chile, on 8 November, and another at the ENEFA conference in Valdivia (Chile) on 14 November. I also gave a talk as part of the ChiSocNet series of seminars in Santiago, 11 November.
A few years ago, when hopes to leverage technology to build a more humane “sharing” economy had not yet completely vanished, it was often believed that the most interesting policy experiments were to be found at the local level of cities, not states. One of those was the urban-planning concept of a 15-minute city, aiming to make any essential amenities such as schools and shops accessible within a 15-min walk or bike ride. Launched in Paris before receiving enthusiastic support worldwide, it was part of the current mayor’s latest re-election campaign.
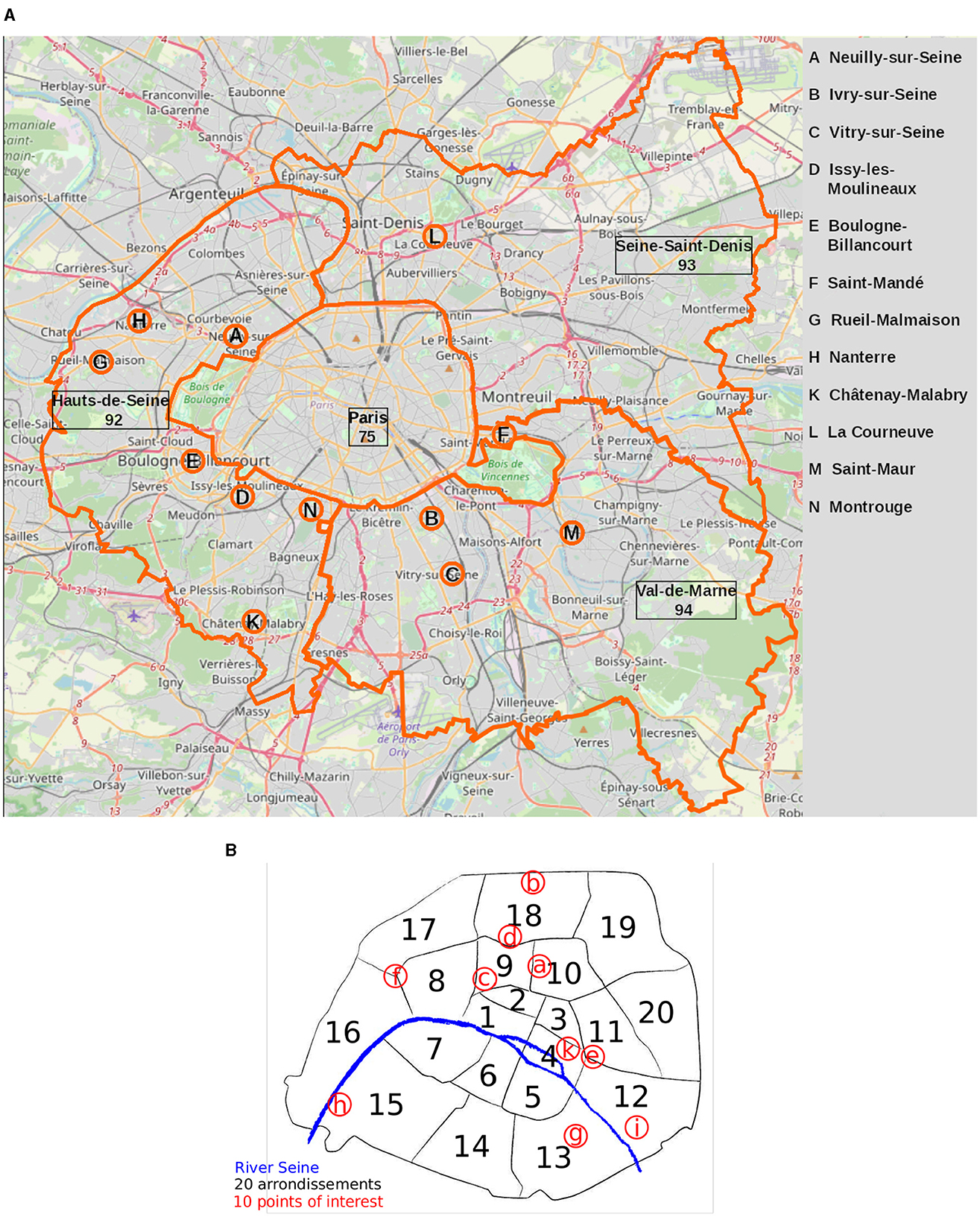
Fast forward to today, and how actually far is Paris from the 15-min goal? Sarah J. Berkemer and I have endeavoured to answer this question in a just-published article (available in open access!) with three brilliant ENSAE students (Marie-Olive Thaury, Simon Genet and Léopold Maurice). We harness open map data from the large participatory project Open Street Map and geo-localized socio-economic data from official statistics (Insee) to fill this gap.
While the city of Paris is rather homogeneous, we show that it is nonetheless characterized by remarkable inequalities between a highly accessible city centre (though with some internal differences in terms of types of amenities) and a less equipped periphery, where lower-income neighborhoods are more often found. Heterogeneity increases if we consider Paris together with its immediate surroundings, the “Petite Couronne,” where large numbers of daily commuters and other users of city facilities live.
We find that this ambitious urban planning objective cannot be achieved without addressing existing socio-economic inequalities, and that especially in a big city like Paris, it cannot be confined within the narrow boundaries of the municipality itself, without also including the city’s immediate surroundings.
One reason why I am particularly proud of this work is that it demonstrates how far research-informed teaching can go. Most higher education is about familiarizing students with generally accepted and confirmed knowledge, without going beyond the state of the art. This is certainly important and in all cases a “safe” bet, but does not give students a sense of what it means to push the boundaries further. This project was an opportunity to do so. It gave students the role of researchers – our peers – letting them play the role in full and showing them all the back-office work that lies behind publications (from drafting to responding to reviews and copy-editing), and that is (too) often occluded from students’ view. There’s probably more to experiment around this model.
Last week with the Diplab team, we spent two exciting days at the European Parliament in Brussels, engaging in profound discussions with and about platform workers as part of the 4th edition of the Transnational Forum on Alternatives to Uberization.
Together, we delved into the intricacies of the human labor that fuels artificial intelligence and ensures safe participation to social media. Together, we discussed workers’ expectations, concerns and common struggles to move forward toward a world in which where technology serves all humans equally and responsibly.
Digital labor is at the heart of our evolving economies. To address the specific challenges and developments in the Middle East and Africa (MEA), we are launching a dedicated chapter of INDL for the region.
This conference provides a unique platform to present research related to the MEA region, both ongoing and/or burgeoning. The conference offers opportunities for scholars and practitioners to engage with topics such as platformization, automation, gig economy dynamics, and technology-mediated labor.
INDL-MEA will feature three tracks: one in Arabic, one in English, and one in French, reflecting the linguistic diversity of the region.
Topics
Submissions must be in reference to the MEA region, for instance: in perspective, case studies, or focus.
Submission topics may include but are not limited to
Case studies examining platforms, gig economy workers, and online digital labor in MEA
Exploring algorithmic management practices in work processes, recruiting, and HR in MEA
Issues of digital platform labor on gender and inclusion in the MEA region
Consequences of the shift to digital labor on workers, businesses, economies, and labor markets in MEA
Effects of remote work and digital labor on employee well-being and productivity in MEA
Policy responses to the rise of digital labor and automation in MEA, including regulatory measures and government intervention
Strategies for organizing digital workers and managing geographically distributed workforces in MEA
Intersectional perspectives on digital labor in MEA
Exploring AI and digital labor through a decolonial lens in MEA
Challenges posed by Generative AI to human labor in MEA
Submissions
We invite submissions of anonymized abstracts for papers, case studies, and policy briefs related to these topics. Abstracts, up to 500 words, can be submitted in Arabic, English, or French through our website INDL-MEA.
Important Dates
Deadline for submissions: January 31, 2024
Acceptance notification: February 15, 2024
Registration opens: TBA
INDL-MEA conference date: May 28, 2024
Together, let’s foster a thought-provoking dialogue and contribute to shaping the future of digital labor in the Middle East and Africa.
For more information, please see the INDL website.
Within the Horizon-Europe project AI4TRUST, we published a first report presenting the state of the art in the socio-contextual basis for disinformation, relying on a broad review of extant literature, of which the below is a synthesis.
What is disinformation?
Recent literature distinguishes three forms:
‘misinformation’ (inaccurate information unwittingly produced or reproduced)
‘disinformation’ (erroneous, fabricated, or misleading information that is intentionally shared and may cause individual or social harm)
‘malinformation’ (accurate information deliberately misused with malicious or harmful intent).
Two consequences derive from this insight. First, the expression ‘fake news’ is unhelpful: problematic contents are not just news, and are not always false. Second, research efforts limited to identifying incorrect information alone, without capturing intent, may miss some of the key social processes surrounding the emergence and spread of problematic contents.
How does mis/dis/malinformation spread?
Recent literature often describes the characteristics of the process of diffusion of mis/dis/malinformation in terms of ‘cascades’, that is, the iterative propagation of content from one actor to others in a tree-like fashion, sometimes with consideration of temporality and geographical reach. There is evidence that network structures may facilitate or hinder propagation, regardless of the characteristics of individuals: therefore, relationships and interactions constitute an essential object of study to understand how problematic contents spread. Instead, the actual offline impact of online disinformation (for example, the extent to which online campaigns may have inflected electoral outcomes) is disputed. Likewise, evidence on the capacity of mis/dis/malinformation to spread across countries is mixed. A promising perspective to move forwards relies on hybrid approaches mixing network and content analysis (‘socio-semantic networks’).
What incentivizes mis/dis/malinformation?
Mis/dis/malinformation campaigns are not always driven solely by political tensions and may also be the product of economic interest. There may be incentives to produce or share problematic information, insofar as the business model of the internet confers value upon contents that attract attention, regardless of their veracity or quality. A growing, shadow market of paid ‘like’, ‘share’ and ‘follow’ inflates the rankings and reputation scores of web pages and social media profiles, and it may ultimately mislead search engines. Thus, online metrics derived from users’ ratings should be interpreted with caution. Research should also be mindful that high-profile disinformation campaigns are only the tip of the iceberg, low-stake cases being far more frequent and difficult to detect.
Who spreads mis/dis/malinformation?
Spreaders of mis/dis/malinformation may be bots or human users, the former being increasingly controlled by social media companies. Not all humans are equally likely to play this role, though, and the literature highlights ‘super-spreaders’, particularly successful at sharing popular albeit implausible contents, and clusters of spreaders – both detectable in data with social network analysis techniques.
How is mis/dis/malinformation adopted?
Adoption of mis/dis/malinformation should not be taken for granted and depends on cognitive and psychological factors at individual and group levels, as well as on network structures. Actors use ‘appropriateness judgments’ to give meaning to information and elaborate it interactively with their networks. Judgments depend on people’s identification to reference groups, recognition of authorities, and alignment with priority norms. Adoption can thus be hypothesised to increase when judgments are similar and signalled as such in communication networks. Future research could target such signals to help users in their contextualization and interpretation of the phenomena described.
Multiple examples of research in social network analysis can help develop a model of the emergence and development of appropriateness judgements. Homophily and social influence theories help conceptualise the role of inter-individual similarities, the dynamics of diffusion in networks sheds light on temporal patterns, and analyses of heterogeneous networks illuminate our understanding of interactions. Overall, social network analysis combined with content analysis can help research identify indicators of coordinated malicious behaviour, either structural or dynamic.
I had the privilege and pleasure to visit Madagascar in the last two weeks. I had an invitation from Institut Français where I participated in a very interesting panel on “How can Madagascar help us rethink artificial intelligence more ethically?”, with Antonio A. Casilli, Jeremy Ranjatoelina et Manovosoa Rakotovao. I also conducted exploratory fieldwork by visiting a sample of technology companies, as well as journalists and associations interested in the topic.
A former French colony, Madagascar participates in the global trend toward outsourcing / offshoring which has shaped the world economy in the past two decades. The country harnesses its cultural and linguistic heritage (about one quarter of the population still speak French, often as a second language) to develop services for clients mostly based in France. In particular, it is a net exporter of computing services – still a small-sized sector, but with growing economic value.
Last year, a team of colleagues has already conducted extensive research with Madagascan companies that provide micro-work and data annotation services for French producers of artificial intelligence (and of other digital services). Some interesting results of their research are available here. This time, we are trying to take a broader look at the sector and include a wider variety of computing services, also trying to trace higher-value-added activities (like computer programming, website design, and even AI development).
It is too early to present any results, but the big question so far is the sustainability of this model and the extent to which it can push Madagascar higher up in the global technology value chain. Annotation and other lower-level services create much-needed jobs in a sluggish economy with widespread poverty and a lot of informality; however, these jobs attract low recognition and comparatively low pay, and have failed so far to offer bridges toward more stable or rewarding career paths. More qualified computing jobs are better paid and protected, but turnover is high and (national and international) competition is tough.
At policy level, more attention should be brought to the quality of these jobs and their longer-term stability, while client tech companies in France and other Global North countries should take more responsibility over working conditions throughout their international supply chains.
I’m sooo glad to be in Berlin for the 6th edition of this beloved INDL-6 conference, which is taking place at Weizenbaum Institut!
INDL started as a small-scale, informal, little-funded project, aiming to create linkages between academics and students interested in the transformations of labour brought about by digital technologies. We first met in Paris in Spring 2017, then in Louvain-la-Neuve (Belgium) a few months later, and in both cases, a smallish 20-people room was enough for all. Back then, we called ourselves ENDL (where E stood for “European”).
But in 2019, we partnered with Toronto-based colleagues and upgraded to INDL, moving from European to International level. We started a cycle of conferences which initially remained rather small-scaled, and for two years had to take place online owing to the pandemic crisis. Things started to change in 2022, when colleagues from Greece proposed to restart an in-person version of the conference which eventually took place in Athens. It was also the first time that we launched a call for papers, rather than just limiting ourselves to invited speakers, and the conference was a huge success, with almost a hundred participants and sessions running in parallel.
This year edition’s follows the same format, and I’m so happy to see that a large community is forming around this topic. It’s good to see some people who already attended last year or even before, together with many new faces, and numbers continuing to grow (this year, we have three instead of just two parallel sessions!).
Together with the parallel sessions, this year’s event includes three keynotes, an arts-meets-science session, and a regulation-oriented debate on due diligence processes and the technology supply chain. Weizenbaum Institut is a wonderful place and has made available funding, support, and an incredibly committed team of colleagues, students, and volunteers who are making this conference a success.
For the programme, link to the livestreaming of plenaries and main sessions, and further information, please see indl.network.
Most of my current research aims to unpack artificial intelligence (AI) from the viewpoint of its commercial production, looking in particular at the human resources needed to prepare the data it needs – whence my studies on the data work and annotation market. However, for once, I am focusing on AI as a set of scientific theories and tools, regardless of their market positioning; indeed, I have joined a team of science-of-science specialists to study the disciplinary origins and subsequent spread of AI over time.
In a newly published, open-acces article, we unveil the disciplinary composition of AI, and the links between its various sub-fields. We question a common distinction between ‘native’ and ‘applicative’ disciplines, whereby only the former (typically confined to statistics, mathematics, and computer science) produce foundational algorithms and theorems for AI. In fact, we find that the origins of the field are rather multi-disciplinary and benefit, among others, from insights from cognitive science, psychology, and philosophy. These intersecting contributions were most evident in the historical practices commonly known as ‘symbolic systems’. Later, different scientific fields have become, in turn, the central originating domains and applicators of AI knowledge, for example operations research, which was for a long time one of the core actors of AI applications related to expert systems.
While the notion of statistics, mathematics and computer science as native disciplines has become more relevant in recent times, the spread of AI throughout the scientific ecosystem is uneven. In particular, only a small number of AI tools, such as dimensionality reduction techniques, are widely adopted (for example, variants of these techniques have been in use in sociology for decades). But if transfer of AI is largely ascribable to multi-disciplinary interactions, very few of them exist. We observe very limited collaborations between researchers in disciplines that create AI and researchers in disciplines that only (or mainly) apply AI. The small core of multi-disciplinary champions who interact with both sides, and the presence of a few multi-disciplinary journals, sustains the whole system.
Inter- and multi-disciplinary interactions are essential for AI to thrive and to adequately support scientific research in all fields, but disciplinary boundaries are notoriously hard to break. Strategies to better reward inter-disciplinary training, publications, and careers, are thus essential. Of course the potential for AI to significantly advance knowledge is still (largely) to be proven, and there have been disappointing experiences with, for example, the comparatively limited effectiveness of these tools in research on Covid-19. In all cases, the status quo is not ideal, and important steps forward are now needed.
We establish these results by analyzing a large corpus of scientific papers published between 1970 and 2017, extracted from Microsoft Academic Graph through the AI keywords used by the authors, and explored with different relational structures among the scientometric data (keyword co-occurrence network, authors’ collaboration network).
Full citation: Floriana Gargiulo, Sylvain Fontaine, Michel Dubois, Paola Tubaro. A meso-scale cartography of the AI ecosystem. Quantitative Science Studies, 2023; doi: https://doi.org/10.1162/qss_a_00267