Twitter conversations are one way through which participants in an event engage with the programme, comment and discuss about the talks they attend, prolong questions-and-answers sessions. Twitter feeds have become part of the official communication strategy of major events and serve documentation and information purposes, both for attendees and for outsiders. While tweeting is becoming more an more a prerogative of “official” accounts in charge of event communication, it is also a potential tool in the hands of each participant, allowing anyone to join the conversation at least in principe. Earlier, I have discussed how the Twitter discussion networks formed at the OuiShare Fest 2016, a major gathering of the collaborative economy community that took place last May in Paris, were one opportunity to see such mechanisms in place.
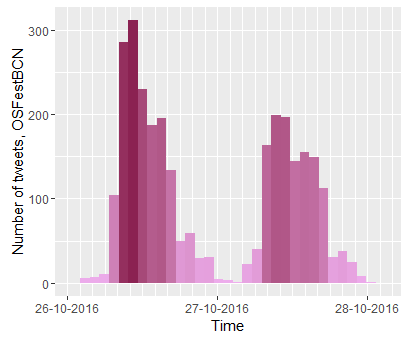
Here is a similar analysis, performed after the OuiShareFest Barcelona – the Spanish-language version of the event that I had the chance of attending last week. The size of this event is smaller than its Paris counterpart but nonetheless impressive: I mined 3497 tweets with the official hashtag of the event, #OSfestBCN, mostly written during the two days of the event (my count stopped the day after). Do Twitter #OSfestBCN conversations describe the community?
First, when did people tweet? As often happens, there are more tweets on the first than the second day of the event, and there are more tweets during the first hours of each day, though the difference between morning and afternoon is not dramatic; tweeting declines only at night, when the fest’s activities are suspended. Online activity is not independent of what happens on the ground – quite on the contrary, it follows the timings of physical activity.

Who tweeted most? Obviously the official @OuiShare_es account, who published 630 tweets – nine times as many as the second in the ranking. Those who follow immediately are all individuals, who have between 50-70 tweets each.
Who tweeted with whom? What interests me most are conversations – who interacts with whom. The most explicit way of seeing this with Twitter data is to look at replies: who replied to whom. This corresponds to a small social network of 134 tweeters (the coloured points in the next Figure). Ties among them are represented as lines in the figure, and the size of points depends on the number of their incoming ties, that is, the number of replies received. Beyond the official @OuiShare_es account, several tweeters receive a lot of replies: they are mostly speakers, track leaders, or otherwise important actors in the community.

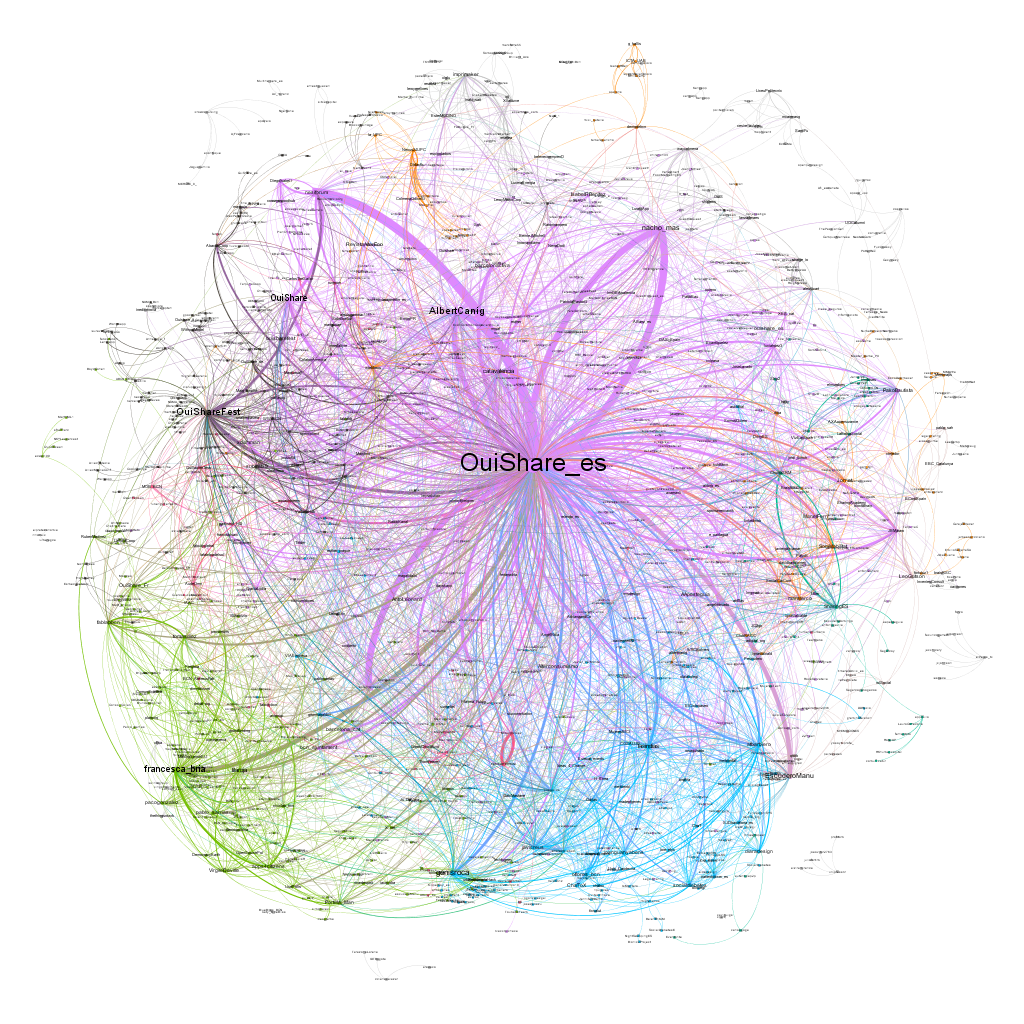
Now, who tweeted about whom? This is also an important aspect of Twitter conversations. We can capture it with the social network of mentions, associating each tweeter with those they mentioned, and counting the number of times they did so. This will be a larger network (with 2553 mentions) compared to the net of replies, as mentions can be of many types and also include retweets.
The below figure represents the network of mentions. As before, the colored points are tweeters (the larger they, the more often they have been mentioned by others), while lines between them are mentions (the thicker they are, the higher the number of times a user has mentioned another). Colors represent a measure called “modularity”, which identifies clusters of nodes whereby internal connections are stronger than the connections they have with nodes in other clusters; so for example, a purple node is more likely to have mentioned other purple nodes, than blue nodes.
Modularity is computed based only on counts of ties, without considering the nature of their conversations (what the mention is about) ou other qualities of nodes (gender, nationality, language of tweeters, etc.). And yet, it clearly identifies specific sub-communities. The very numerous, central purple nodes are the OuiShare community: connectors, activists, and others close to the organization especially within Spain. The green nodes at the bottom-left are the catalan community, including representatives of local authorities,notably the Barcelona municipality. The blue nodes at the bottom are different actors and groups from other parts of Spain. The few black nodes on the left are the international OuiShare community, and the sparse orange ones at the top are other international actors.

This analysis is part of a larger research project, “Sharing Networks“, led by Antonio A. Casilli and myself, and dedicated to the study of the emergence of communities of values and interest at the OuiShare Fest 2016. Twitter networks will be combined with other data on networking – including informal networking which we are capturing through a (perhaps old-fashioned, but still useful!) survey.
The analyses and visualizations above were done with the package TwitteR in R as well as Gephi.