I co-organize this Satellite to the NETSCI2018 Conference in Paris, 12 June 2018. We are now accepting submissions of proposals for presentations.
Information on the Satellite
In traditional research paradigms, sociology handles small but rich networks where the richness of network attributes is derived from the specific buildup of the data collection process. In the sociological approach, differences among nodes and edges are key to describe network properties and the ensuing dynamical social processes. Instead, the complex systems tradition deals with large but poor networks. Assuming statistical equivalence of graph entities, a mean field treatment serves to describe the aggregate properties of the network. Today’s network datasets contain an unprecedented quantity of relational information at all, and between all, the possible levels: individuals, social groups, political structures, economical actors, etc. We finally deal with large and rich network structures that expose the implicit limitations of the two abovementioned approaches: the traditional methods from social science cannot be upscaled because of their algorithmic complexity and those from complex systems lose track of the complex nature of the actors, their relationships and their processes. This workshop has the aim of developing an interdisciplinary reflection on how methods from social science could be upscaled to large network structures and on how methods from complex systems could be downscaled to deal with small heterogeneous structures.
We are proud that five prominent international scholars are our invited speakers: Camille Roth, SciencesPo Paris; Matthieu Latapy, LIP6UPMC Paris; Alessandro Lomi, ETH Zurich; Fariba Karimi, GESIS Cologne; Noshir Contractor, Northwestern University.
Contributions
We invite abstracts of published or unpublished work for contributed talks to take place at the satellite symposium. We expect a broad range of topics to be covered, across theory, methodology, and application to empirical data, relating to an interdisciplinary reflection on how methods from social science could be upscaled to large network structures and on how methods from complex systems could be downscaled to deal with small heterogeneous structures.
Submissions are required to be at most 650 words long and should include the following information: title of the talk, author(s), affiliation(s), email address(es), name of the presenter, abstract. Papers or submissions longer than 1 page will not be accepted.
Important dates
Abstract submission deadline is March 25, 2018. Notification of acceptance will be no later than April 23, 2018.
All participants and accepted speakers will have to register through the NETSCI2018 website.
Fueled by increasingly powerful computing and visualization tools, research on social networks is flourishing. However, it raises ethical issues that largely escape existing codes of conduct and regulatory frameworks. The economic power of large data platforms, the active participation of network members, the spectrum of mass surveillance, the effects of networking on health, the place of artificial intelligence: so many questions in search of solutions.
Social networks, what are we talking about?
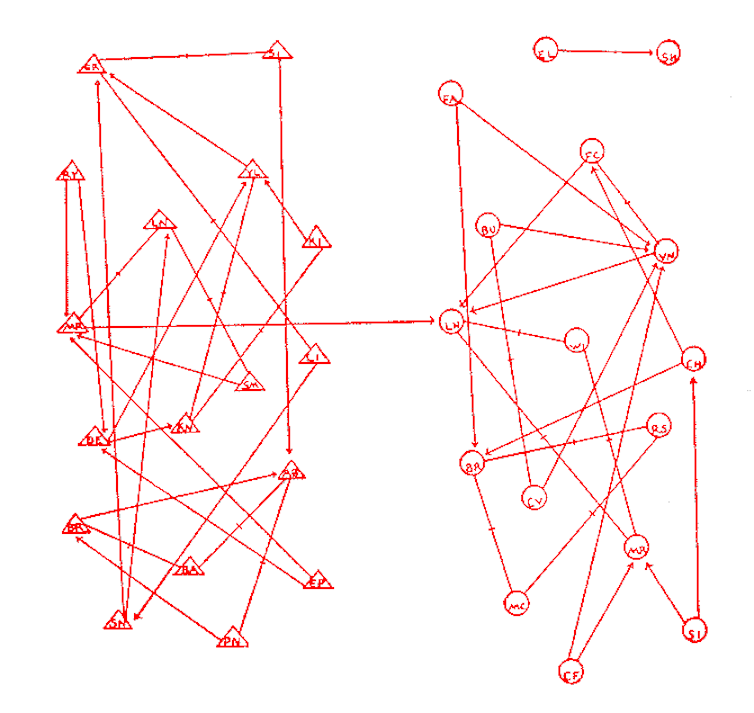
The expression “social network” has become common, but those who use it to refer to social media as Facebook or Instagram often ignore its origin and its true meaning. The study of social networks precedes the advent of digital technologies. Since the 1930s, sociologists have been conducting surveys to describe the structures of relationships that unite individuals and groups: their “networks”. These include, for example, advice relationships between employees of a company, or friendship ties between students in a school. These networks can be represented as points (students) united by lines (links).
Figure 1 : a social network of friendship ties between students in a school. Circles = girls, triangles = boys, arrows = ties. J.L. Moreno, Who shall survive? 1934.
Before any questioning on the social aspects of Facebook and Twitter, this research shed light on, for example, marital role segregation, importance of “weak ties” in job search, informal organization of firms, diffusion of innovations, formation of business elites, social support for the sick or elderly. Designers of digital platforms such as Facebook have picked up some of the analytical principles on which these works were based, developing them with the mathematical theory of graphs (though often with less attention to the social issues involved).
Early on, researchers in this field realized that the traditional principles of research ethics (focusing on informed consent of study participants and anonymization of data) were difficult to ensure. By definition, social networks research is never about a single individual, but about relationships between this individual and others – their friends, relatives, collaborators or professional advisors. If the latter are reported by the respondent but are not themselves included in the study, it is difficult to see how their consent could be obtained. What’s more, results can be difficult to anonymize, in that visuals are sometimes disclosive even in the absence of personal identifiers.
Ethics in the digital society: a minefield
Academics have long been thinking about these ethical difficulties, to which a special issue of the prestigious Social Networks journal was dedicated as far back as 2005. Today, researchers’ dilemmas are exacerbated by the increased availability of relational data collected and exploited by digital giants like Facebook or Google. New problems arise as the boundaries between “public” and “private” spheres become confused. To what extent do we need consent to access messages that digital service users send to their contacts, their “retweets”, or their “likes” on their friends’ walls?
These sources of information are often the property of commercial enterprises, and the algorithms they use likely bias observations. For example, can we interpret in the same way a contact created spontaneously by a user, and a contact created as a result of an automated recommendation system? In short, the data do not speak for themselves, and before thinking about their analysis, we must question the conditions of their use and the methods of their production. They largely depend on the software architectures imposed by platforms as well as their economic and technical choices. There is a real power asymmetry between platforms – often the property of large multinational companies – and researchers – especially those working in the public sector, and whose objectives are misaligned with investors’ priorities. Negotiations (if possible at all) are often difficult, resulting in restrictions to proprietary data access – particularly penalizing for public research.
Other problems arise as a researcher may even use paid crowdsourcing to produce data, using platforms like Amazon Mechanical Turk to ask large numbers of users to complete a questionnaire, or even to download their online contact lists. But these services raise numerous questions in terms of workers’ rights, working conditions and appropriation of the product of work. The resulting uncertainty hinders research that could otherwise have a positive impact on knowledge and on society at large.
Availability of online communication and publication tools, which many researchers are now seizing, increases the likelihood that research results may be diverted for political or business purposes. If the interest of military and police circles for the analysis of social networks is well known (Osama Bin Laden was allegedly located and neutralised following the application of social network analysis principles), these appropriations are more frequent today, and less easily controllable by researchers. A significant risk is the use of these principles to suppress civic and democratic movements.
Restrictions and prohibitions would likely aggravate the constraints that already weigh on researchers, without helping them overcome these obstacles. Rather, it is important to create conditions for trust and enable researchers to explore the full extent and importance of online and offline social networks – allowing them to capture salient economic and social phenomena while remaining respectful of people’s rights. Researchers should take an active role, participating in the co-construction of an adequate ethical framework, grounded in their experience and self-reflective attitude. A bottom-up process involving academics as well as citizens, civil society associations, and representatives of public and private research organizations could then feed these ideas and thoughts back to regulators (such as ethics committees).
With a group of colleagues from Universitat Autònoma de Barcelona and in Collaboration with OuiShare, we are studying networking at the event. The OuiShare Fest aims, among other things, to bring people together: we want to see how interactions between participants facilitate circulation of ideas and possibly give rise to future collaborations.
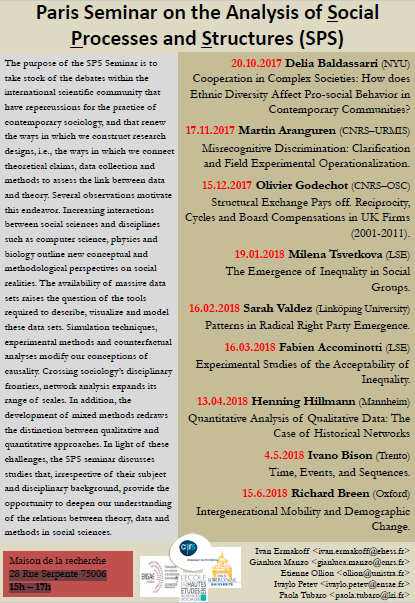
Our inter-disciplinary, inter-institutional SPS seminar (Paris Seminar on the Analysis of Social Processes and Structures) has just started its second edition! Its purpose is to take stock of the debates within the international scientific community that have repercussions on the practice of contemporary sociology, and that renew the ways in which we construct research designs, i.e., the ways in which we connect theoretical claims, data collection and methods to assess the link between data and theory. Several observations motivate this endeavor. Increasing interactions between social sciences and disciplines such as computer science, physics and biology outline new conceptual and methodological perspectives on social realities. The availability of massive data sets raises the question of the tools required to describe, visualize and model these data sets. Simulation techniques, experimental methods and counterfactual analyses modify our conceptions of causality. Crossing sociology’s disciplinary frontiers, network analysis expands its range of scales. In addition, the development of mixed methods redraws the distinction between qualitative and quantitative approaches. In light of these challenges, the SPS seminar discusses studies that, irrespective of their subject and disciplinary background, provide the opportunity to deepen our understanding of the relations between theory, data and methods in social sciences.
Research on social networks is experiencing unprecedented growth, fuelled by the consolidation of network science and the increasing availability of data from digital networking platforms. However, it raises formidable ethical issues that often fall outside existing regulations and guidelines. New tools to collect, treat, store personal data expose both researchers and participants to specific risks. Political use and business capture of scientific results transcend standard research concerns. Legal and social ramifications of studies on personal ties and human networks surface.
We invite contributions from researchers in the social sciences, economics, management, statistics, computer science, law and philosophy, as well as other stakeholders to advance the ethical reflection in the face of new research challenges.
The workshop will take place on 5 December 2017 (full day) at MSH Paris-Saclay, with open keynote sessions to be held on 6 December 2017 (morning) at Hôtel de Lauzun, a 17th century palace in the heart of historic Île de la Cité.
Let us know if you wish to be panel discussant or session chair by 20 October 2017 (send to: recsna17@msh-paris-saclay.fr).
Acceptance notifications will be sent by 31 October 2017.
Registration is free but mandatory: speakers (and discussants and chairs) should register between 15 October and 15 November 2017, other attendees by 30 November 2017.
Keynote Speakers
José Luis Molina, Autonomous University of Barcelona, “HyperEthics: A Critical Account” Bernie Hogan, Oxford Internet Institute, “Privatising the personal network: Ethical challenges for social network site research”
Scientific Committee
Antonio A. Casilli (Telecom ParisTech, FR), Alessio D’Angelo (Middlesex University, UK), Guillaume Favre (University of Toulouse Jean-Jaurès, FR), Bernie Hogan (Oxford Internet Institute, UK), Elise Penalva-Icher (University of Paris Dauphine, FR), Louise Ryan (University of Sheffield, UK), Paola Tubaro (CNRS, FR).
I’m excited to report that earlier this month, I ran the second wave of data collection for our Sharing Networks research project at OuiShare Fest 2017!
Publicizing the survey at OuiShare Fest 2017
To understand how people form and reinforce face-to-face network ties at such an event, I fielded a questionnaire with the help of a committed and effective team of co-researchers. It is a “name generator” asking respondents to name those they knew before the OuiShare Fest, and met again there (“old frields”); and those they met during the event for the first time (“new contacts”). Participants then have to choose those among their “old” and “new” contacts, that they would like to contact again in future for joint projects or collaborations.
Interestingly, my good old pen-and-paper questionnaire still gives a lot of insight that digital data from social media cannot provide – just like a highly computer literate community such as this feels the need to meet physically in one place every year for a few days. Like trade fairs that flourish even more in the internet era, the OuiShare Fest gathers more participants at each edition. They meet in person there, which is why they are to be invited to respond in person too.
I’m so excited that earlier this month, I ran the second wave of data collection for my Sharing Networks research project at OuiShare Fest 2017!
The study aims to map the collaborative economy community that gathers at OuiShare Fest, looking at how people network and how this fosters the emergence of new trends and topics.
During the event, a small team of committed and effective co-researchers helped me interview participants. We used a questionnaire with a “name generator” format, typically used in social network analysis to elicit people’s connections and reconstitute their social environment.
Specifically, we asked respondents to name people they knew before the
Results of our Sharing Networks 2016 survey have now become a T-shirt.
OuiShare Fest, and met again there (“old friends”), and people they met during the Fest for the first time (“new contacts”). Then we asked them to choose, from among the “old” and “new” they had named, those they would like to contact again with soon, for example for joint projects or collaborations.
I am very happy with the result: 160 completed interviews over three half-days! But it is still not enough: participants to the Fest were much more numerous than that, and in social network analysis, it is well-known that sampling is insufficient, and one needs to get as close to exhaustiveness as possible.
Therefore, for those OuiShare Fest 2017 participants that we did not manage to interview, there is now an opportunity to complete the questionnaire online.
If you were at the Fest and we did not talk to you, please do participate now! It takes less than 8 minutes, and you will help the research team as well as the organization of the Fest.
Many thanks to the team of co-researchers who helped me, the OuiShare team members who supported us, and all respondents.
More information about the Sharing Networks study is available here.
Highlights from results of last years’ Sharing Networks survey are available here.
The OuiShare Fest brings together representatives of the international collaborative economy community. One of its goals is to expose participants to inspiring new ideas, while also offering them an opportunity for networking and building collaborative ties.
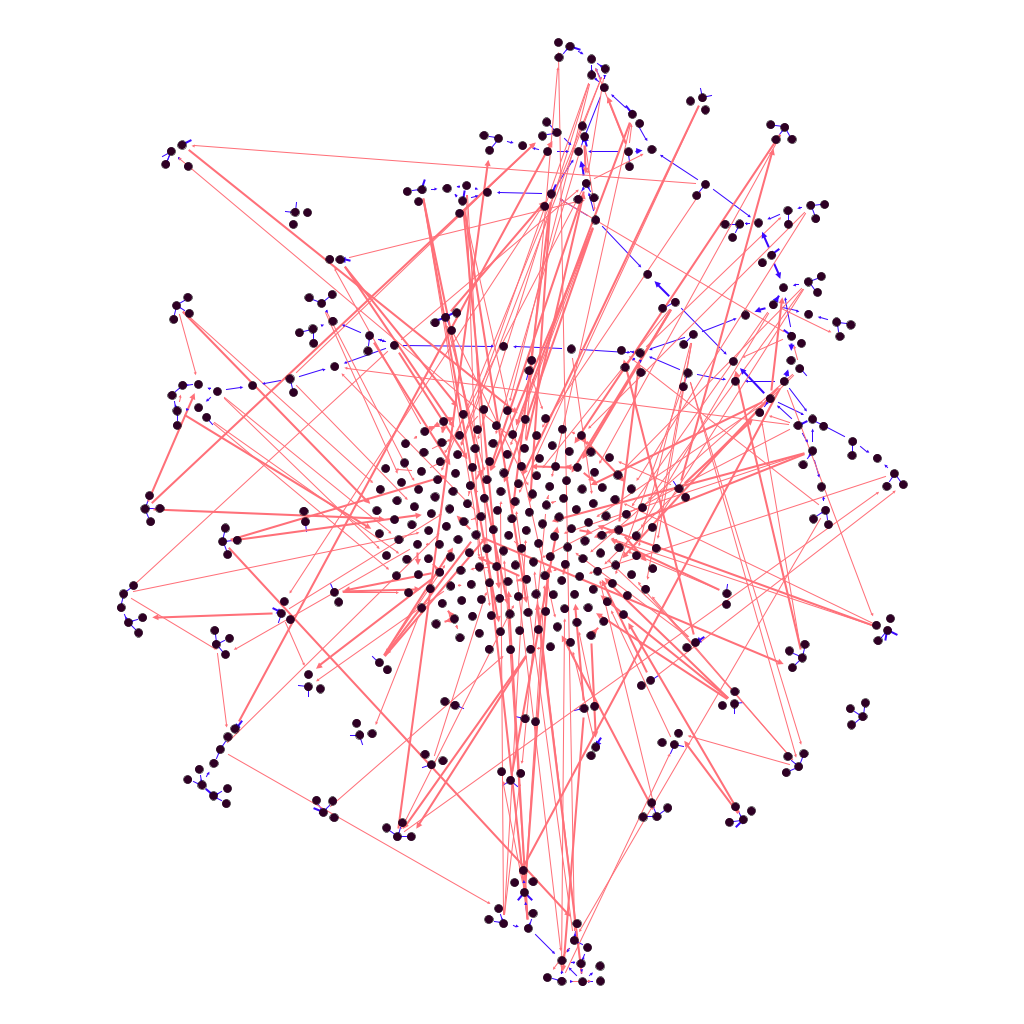
At the 2016 OuiShare Fest, we ran a study of people’s networking. Attendees, speakers and team members were asked to complete a brief questionnaire, on paper or online.Through this questionnaire, we gained information on the relationships of 445 persons – about one-third of participants.
Ties that separate: the inheritance of past relationships
For many participants, the Fest was an opportunity to catch up with others they knew before. Of these relations, half are 12 months old at most. About 40% of them were formed at work; 15% at previous OuiShare Fests or other collaborative economy experiences; 9% can be ascribed to living in the same town or neighborhood; and 7% date back to school time.
Figure 1: pre-existing ties
Figure 1 is a synthesis of these “catching-up-with-old-friends” relationships, in the shape of a network where small black dots represent people and blue lines represent social ties between them. At the center of the graph are “isolates”, participants who had no pre-existing relationship among OuiShare Fest attendees. The remaining 60% have prior connections, but form part of separate clusters. Some of them (27%) form a rather large component, visible at the top of the figure, where each member is directly or indirectly connected to anyone else in that component. There are also two medium-sized clusters of connected people at the bottom. The rest consists of many tiny sub-groups, mostly of 2-3 individuals each.
Ties that bind: new acquaintances made at the event
Participants told us that they also met new persons at the Fest. Figure 2 enriches Figure 1 by adding – in red – the new connections that people made during the event. The ties formed during the Fest connect the clusters that were separate before: now, 86% of participants are in the largest network component, meaning that any one of them can reach, directly or indirectly, 86% of the others.
I am now in Montréal, where I participated, last Friday, in a panel on Open Data at “Science & You” international conference. It was interesting for me to reflect on how the picture has changed since my previous panel on the same topic – in Kiev in 2012. Back then, we were busy trying to convince public administrations that data opening was good for transparency and could help improve services to communities. Since then, a lot of attempts have been made in numerous countries – local authorities often pioneering the process, followed only later by central governments (one example cited in my panel was Québec City). What is made open is typically information from public registers (first names of newborns, records of road accidents) and increasingly, from technological devices and sensors (bus traffic information).
There are some conditions to be met for a dataset to be said “open”:
Technically, it needs to be “raw”, detailed, digital and reusable. The French Interior Ministry released results of the first round of the recent presidential elections within a few days, at polling station level. This is sufficiently detailed (with over 69,000 polling stations throughout the country), raw (allowing aggregations, comparisons etc.), and digital/reusable (so much so that the newspaper Le Monde could develop a user-friendly application to let readers easily check results in their neighborhoods). Some would also insist that “open” data should be released in non-proprietary formats (better .csv than .xls, for example).
Legally, the data must come with a license that allows re-use by third parties (typically within the Creative Commons family). Ideally, no type of reuse should be ruled out (including somewhat controversially, commercial / for-profit reuse).
Economically, the data should be available to all for free (or at least with minimal charges if data preparation requires extra work or expenses).
If in the past few years, a lot of thought has been devoted to the “ideal” conditions for data opening and how this would positively affect public service, the data landscape has now significantly changed.
Each speaker briefly presented a case study that involved visualization, and all were great in conveying exciting albeit complex ideas in a short time span. What follows is a short summary of the main insight (as I saw it).